Wariacyjne metody bayesowskie to rodzina technik aproksymacji nierozwiązalnych całek powstających we wnioskowaniu bayesowskim i uczeniu maszynowym . Są one zwykle używane w złożonych modelach statystycznych składających się z obserwowanych zmiennych (zwykle określanych jako „dane”), a także nieznanych parametrów i zmiennych ukrytych , z różnymi rodzajami relacji między trzema typami zmiennych losowych , które można opisać za pomocą modelu graficznego . Jak to jest typowe we wnioskowaniu bayesowskim, parametry i zmienne latentne są grupowane razem jako „zmienne nieobserwowane”. Wariacyjne metody bayesowskie są używane głównie do dwóch celów:
- Aby zapewnić analityczne przybliżenie prawdopodobieństwa a posteriori nieobserwowanych zmiennych, w celu wnioskowania statystycznego na temat tych zmiennych.
- Aby wyprowadzić dolną granicę dla marginalnego prawdopodobieństwa (czasami nazywanego „dowodem”) obserwowanych danych (tj. marginalnego prawdopodobieństwa danych danego modelu, z marginalizacją wykonywaną na nieobserwowanych zmiennych). Jest to zwykle używane do przeprowadzania wyboru modelu , przy czym ogólna idea polega na tym, że wyższe marginalne prawdopodobieństwo dla danego modelu wskazuje na lepsze dopasowanie danych przez ten model, a zatem większe prawdopodobieństwo, że dany model był tym, który wygenerował dane. (Zobacz także artykuł o współczynniku Bayesa ).
W pierwszym celu (aproksymacji prawdopodobieństwa a posteriori) wariacyjne metody Bayesa są alternatywą dla metod Monte Carlo — w szczególności metod Monte Carlo z łańcuchem Markowa , takich jak próbkowanie Gibbsa — dla przyjęcia w pełni bayesowskiego podejścia do wnioskowania statystycznego w przypadku złożonych rozkładów, które są trudne do bezpośredniej oceny lub próby . W szczególności, podczas gdy techniki Monte Carlo zapewniają aproksymację numeryczną dokładnego odcinka tylnego przy użyciu zestawu próbek, Bayes wariacyjny zapewnia lokalnie optymalne, dokładne rozwiązanie analityczne do przybliżenia odcinka tylnego.
Wariacyjne Bayesa można postrzegać jako rozszerzenie algorytmu EM ( maksymalizacja oczekiwań ) od maksymalnej estymacji a posteriori ( estymacja MAP) pojedynczej najbardziej prawdopodobnej wartości każdego parametru do pełnej estymacji bayesowskiej, która oblicza (przybliżenie) cały rozkład a posteriori parametrów i zmiennych ukrytych. Podobnie jak w EM, znajduje zestaw optymalnych wartości parametrów i ma taką samą naprzemienną strukturę jak EM, opartą na zestawie wzajemnie powiązanych (wzajemnie zależnych) równań, których nie można rozwiązać analitycznie.
W wielu zastosowaniach wariacyjne Bayes tworzy rozwiązania o dokładności porównywalnej do próbkowania Gibbsa z większą szybkością. Jednak wyprowadzenie zestawu równań używanego do iteracyjnego aktualizowania parametrów często wymaga dużej ilości pracy w porównaniu z wyprowadzeniem porównywalnych równań próbkowania Gibbsa. Dzieje się tak nawet w przypadku wielu modeli, które są koncepcyjnie dość proste, jak pokazano poniżej w przypadku podstawowego modelu niehierarchicznego z tylko dwoma parametrami i bez zmiennych ukrytych.
Wyprowadzenie matematyczne
Problem
We wnioskowaniu wariacyjnym rozkład a posteriori nad zbiorem zmiennych nieobserwowanych przy pewnych danych jest aproksymowany przez tzw. rozkład wariacyjny , :




Rozkład jest ograniczony do rodziny rozkładów o prostszej formie (np. rodzina rozkładów Gaussa) niż , wybranych z zamiarem upodobnienia do prawdziwego a posteriori, .

Podobieństwo (lub odmienność) mierzy się w kategoriach funkcji odmienności, a zatem wnioskowanie odbywa się poprzez wybór rozkładu, który minimalizuje .

Rozbieżność KL
Najpopularniejszy typ wariacji Bayes wykorzystuje rozbieżność Kullbacka-Leiblera ( rozbieżność KL) P z Q jako wybór funkcji niepodobieństwa. Ten wybór sprawia, że ta minimalizacja jest wykonalna. Rozbieżność KL jest zdefiniowana jako

Zauważ, że Q i P są odwrotne od tego, czego można by się spodziewać. To użycie odwróconej dywergencji KL jest koncepcyjnie podobne do algorytmu maksymalizacji oczekiwań . (Użycie dywergencji KL w inny sposób daje algorytm propagacji oczekiwania .)
Krnąbrność
Techniki wariacyjne są zwykle używane do tworzenia przybliżenia dla:

Marginalizacja przed obliczeniem w mianowniku jest zazwyczaj niewykonalna, ponieważ np. przestrzeń poszukiwań jest kombinatorycznie duża. Dlatego szukamy przybliżenia, używając .



Dolna granica dowodów
Biorąc pod uwagę, że , powyższa rozbieżność KL może być również zapisana jako

![{\ Displaystyle D_ {\ operatorname {KL} } (Q \ równoległe P) = \ suma _ {\ mathbf {Z}} Q (\ mathbf {Z}) \ lewo [\ log {\ Frac {Q (\ mathbf { Z} )}{P(\mathbf {Z} ,\mathbf {X} )}}+\log P(\mathbf {X} )\right]=\sum _{\mathbf {Z} }Q(\mathbf {Z} )\left[\log Q(\mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]+\sum _{\mathbf {Z} }Q( \mathbf {Z} )\left[\log P(\mathbf {X} )\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70488fe9b787af7d32d3cbaa97479e414601db46)
Ponieważ jest stałą w odniesieniu do i ponieważ jest rozkładem, mamy

![{\ Displaystyle D_ {\ operatorname {KL}} (Q \ parallel P) = \ suma _ {\ mathbf {Z}} Q (\ mathbf {Z}) \ lewo [\ log Q (\ mathbf {Z}) - \log P(\mathbf {Z} ,\mathbf {X} )\right]+\log P(\mathbf {X} )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe7ea8e2d866fa0a91aaab65b66646a27ee2c1ef)
które zgodnie z definicją wartości oczekiwanej (dla dyskretnej zmiennej losowej ) można zapisać w następujący sposób:
![{\ Displaystyle D_ {\ operatorname {KL}} (Q \ równoległe P) = \ mathbb {E} _ {\ mathbf {Q}} \ lewo [\ log Q (\ mathbf {Z}) - \ log P (\ mathbf {Z} ,\mathbf {X} )\right]+\log P(\mathbf {X} )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a8cdf19ada48df35350f6069e8bdb467ea90fa3a)
które można zmienić, aby stać się
![{\ Displaystyle \ log P (\ mathbf {X} ) = D_ {\ operatorname {KL}} (Q \ p równoległy) - \ mathbb {E} _ {\ mathbf {Q}} \ lewo [\ log Q (\ mathbf {Z} )-\log P(\mathbf {Z} ,\mathbf {X} )\right]=D_{\mathrm {KL} }(Q\parallel P)+{\mathcal {L}}(Q )}](https://wikimedia.org/api/rest_v1/media/math/render/svg/014dc584197ed29d710ec90a734d0979fab476e5)
Ponieważ dowód logarytmiczny jest ustalony w odniesieniu do , maksymalizacja końcowego terminu minimalizuje rozbieżność KL od . Dzięki odpowiedniemu doborowi , staje się podatny na obliczenia i maksymalizację. Stąd mamy zarówno przybliżenie analityczne dla a posteriori , jak i dolną granicę dla dowodów (ponieważ rozbieżność KL jest nieujemna).




Dolna granica jest znany jako (ujemny) wariacyjną energii swobodnej analogicznie energia swobodna , ponieważ może on być wyrażony jako negatywnej energii plus entropii z . Termin ten jest również znany jako Evidence Lower Bound , w skrócie ELBO , aby podkreślić, że jest to dolna granica dowodów danych.
![\operatorname {E}_{{Q}}[\log P({\mathbf {Z}},{\mathbf {X}})]](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7e43c3758a771143c7934709ad3198bf43e1ca6)
Dowody
Za pomocą uogólnionego twierdzenia Pitagorasa o dywergencji Bregmana , którego rozbieżność KL jest szczególnym przypadkiem, można wykazać, że:

gdzie jest zbiorem wypukłym, a równość zachodzi, jeśli:


W takim przypadku globalny minimalizator z można znaleźć w następujący sposób:



w którym stała normalizująca to:

Termin ten jest często nazywany w praktyce dolną granicą dowodów ( ELBO ), ponieważ , jak pokazano powyżej.


Zamieniając role i możemy iteracyjnie obliczyć aproksymowane i prawdziwe brzegi modelu i odpowiednio. Chociaż ten schemat iteracyjny gwarantuje zbieżność monotoniczną, zbieżność jest tylko lokalnym minimalizatorem .








Jeżeli ograniczona przestrzeń jest zamknięta w niezależnej przestrzeni, tj . powyższy schemat iteracyjny stanie się tak zwanym przybliżeniem pola średniego, jak pokazano poniżej.


Aproksymacja średniego pola
Zazwyczaj zakłada się, że rozkład wariacyjny rozkłada się na czynniki w pewnym podziale zmiennych latentnych, tj. w przypadku pewnego podziału zmiennych latentnych na ,


Korzystając z rachunku wariacyjnego (stąd nazwa „wariacyjny Bayes”) można wykazać, że „najlepszy” rozkład dla każdego z czynników (pod względem rozkładu minimalizującego rozbieżność KL, jak opisano powyżej) można wyrazić jako:


![q_{j}^{{*}}({\mathbf {Z}}_{j}\mid {\mathbf {X}})={\frac {e^{{\nazwa operatora {E}_{{i \neq j}}[\ln p({\mathbf {Z}},{\mathbf {X}})]}}}{\int e^{{\nazwa operatora {E}_{{i\neq j} }[\ln p({\mathbf {Z}},{\mathbf {X}})]}}\,d{\mathbf {Z}}_{j}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/54a19a4b67e4645e2bfa184a1a77a00eb839e0cc)
gdzie jest oczekiwaniem logarytmu łącznego prawdopodobieństwa danych i zmiennych latentnych, przejętych po wszystkich zmiennych nie w podziale: patrz wyprowadzenie rozkładu .
![\operatorname {E}_{{i\neq j}}[\ln p({\mathbf {Z}},{\mathbf {X}})]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f2139de2e8830491c39b7b999ef34593707d40d9)

W praktyce najczęściej pracujemy logarytmicznie, czyli:
![\ln q_{j}^{{*}}({\mathbf {Z}}_{j}\mid {\mathbf {X}})=\operatorname {E}_{{i\neq j}}[ \ln p({\mathbf {Z}},{\mathbf {X}})]+{\text{stała}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/931ba9fd5d59d6d74dad8cf2a82448fbca0c5ff9)
Stała w powyższym wyrażeniu jest powiązana ze stałą normalizującą (mianownik w powyższym wyrażeniu dla ) i jest zwykle przywracana przez kontrolę, ponieważ resztę wyrażenia można zwykle rozpoznać jako znany typ rozkładu (np. Gaussian , gamma itp.).
Na podstawie właściwości oczekiwań, ekspresja może zwykle być uproszczone do funkcji stałych hiperparametrów tych stanu rozkładu powyżej zmiennych utajonych i oczekiwań (czasem wyższych momentów takich jak wariancji ) zmiennych utajonych nie w bieżącej partycji (tj ukryte zmienne nieuwzględnione w ). Tworzy to cykliczne zależności między parametrami rozkładów względem zmiennych w jednej partycji a oczekiwaniami zmiennych w pozostałych partycjach. To naturalnie sugeruje algorytm iteracyjny , podobnie jak EM ( algorytm maksymalizacji oczekiwań ), w którym oczekiwania (i ewentualnie wyższe momenty) zmiennych latentnych są inicjowane w pewien sposób (być może losowo), a następnie parametry każdego rozkładu są obliczane z kolei przy użyciu bieżących wartości oczekiwań, po czym oczekiwanie nowo obliczonego rozkładu jest odpowiednio ustawiane zgodnie z obliczonymi parametrami. Algorytm tego rodzaju gwarantuje zbieżność .

Innymi słowy, dla każdego z podziałów zmiennych, poprzez uproszczenie wyrażenia na rozkład nad zmiennymi tego podziału i zbadanie funkcjonalnej zależności rozkładu od rozpatrywanych zmiennych, zwykle można określić rodzinę rozkładu (co z kolei determinuje wartość stałej). Wzór na parametry rozkładu będzie wyrażony w postaci hiperparametrów poprzednich rozkładów (które są znanymi stałymi), ale także w postaci oczekiwań funkcji zmiennych w innych podziałach. Zwykle oczekiwania te można uprościć do funkcji oczekiwań samych zmiennych (tj. średnich ); czasami pojawiają się również oczekiwania dotyczące zmiennych do kwadratu (które mogą być związane z wariancją zmiennych) lub oczekiwania wyższych potęg (tj. wyższych momentów ). W większości przypadków rozkłady pozostałych zmiennych będą pochodzić ze znanych rodzin i można znaleźć wzory na odpowiednie oczekiwania. Jednak formuły te zależą od parametrów tych rozkładów, które z kolei zależą od oczekiwań dotyczących innych zmiennych. W rezultacie wzory na parametry rozkładów każdej zmiennej można wyrazić jako szereg równań z wzajemnymi, nieliniowymi zależnościami między zmiennymi. Zwykle nie ma możliwości bezpośredniego rozwiązania tego układu równań. Jednak, jak opisano powyżej, zależności sugerują prosty algorytm iteracyjny, który w większości przypadków gwarantuje zbieżność. Przykład wyjaśni ten proces.
Formuła dwoistości dla wnioskowania wariacyjnego
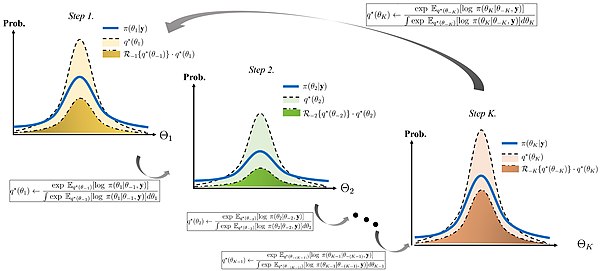
Obrazkowa ilustracja algorytmu wnioskowania wariacyjnego ze współrzędnością wznoszenia za pomocą wzoru na dualność.
Poniższe twierdzenie jest określane jako formuła dwoistości dla wnioskowania wariacyjnego. Wyjaśnia niektóre ważne właściwości rozkładów wariacyjnych stosowanych w wariacyjnych metodach Bayesa.
Twierdzenie Rozważmy dwa Przestrzeń probabilistyczna i z . Załóżmy, że istnieje wspólna dominująca miara prawdopodobieństwa, taka jak i . Pozwolić oznaczają żadnych realnych wartościach zmienną losową o który spełnia . Wtedy obowiązuje następująca równość








![{\ Displaystyle \ log E_ {P} [\ exp h] = {\ tekst {sup}} _ {Q \ ll P} \ {E_ {Q} [h]-D_ {\ tekst {KL}} (Q \ równolegle P)\}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b77d97ef624d72b613687f5ba1dae28f355ea34)
Co więcej, supremum po prawej stronie jest osiągane wtedy i tylko wtedy, gdy się trzyma
![{\displaystyle {\frac {q(\theta)}{p(\theta)}}={\frac {\exp h(\theta)}{E_{P}[\exp h]}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3aa6d2bde96aa9ae886413e7889fd4496dbe710c)
prawie na pewno w przypadku środka prawdopodobieństwa , w którym i oznaczają pochodnych Radona-Nikodyma tych środków prawdopodobieństwa i w odniesieniu do , odpowiednio.


Podstawowy przykład
Rozważmy prosty niehierarchiczny model bayesowski składający się z zestawu obserwacji iid z rozkładu Gaussa , z nieznaną średnią i wariancją . Poniżej szczegółowo omówimy ten model, aby zilustrować działanie wariacyjnej metody Bayesa.
Dla matematycznej wygody w poniższym przykładzie pracujemy w kategoriach precyzji — tj. odwrotności wariancji (lub w wielowymiarowym gaussie, odwrotności macierzy kowariancji ) — a nie samej wariancji. (Z teoretycznego punktu widzenia precyzja i wariancja są równoważne, ponieważ istnieje między nimi zależność jeden do jednego ).
Model matematyczny
Umieszczamy sprzężone rozkłady wcześniejsze na nieznanej średniej i precyzji , tj. średnia również jest zgodna z rozkładem Gaussa, podczas gdy precyzja jest zgodna z rozkładem gamma . Innymi słowy:



W hiperparametrów i w poprzednich dystrybucji są stałe, określone wartości. Można je ustawić na małe liczby dodatnie, aby uzyskać szerokie rozkłady wcześniejsze wskazujące na nieznajomość wcześniejszych rozkładów i .


Otrzymujemy punkty danych, a naszym celem jest wywnioskowanie a posteriori rozkładu parametrów i



Wspólne prawdopodobieństwo
Wspólne prawdopodobieństwo wszystkich zmiennych można zapisać jako

gdzie znajdują się poszczególne czynniki

gdzie

Przybliżenie faktoryzowane
Załóżmy, że , tj. rozkład a posteriori rozkłada się na czynniki niezależne dla i . Tego typu założenie leży u podstaw wariacyjnej metody bayesowskiej. Prawdziwy rozkład a posteriori w rzeczywistości nie uwzględnia tego w ten sposób (w rzeczywistości, w tym prostym przypadku, wiadomo, że jest to rozkład Gaussa-gamma ), a zatem otrzymany wynik będzie przybliżeniem.

Wyprowadzenie q(μ)
Następnie
![{\ Displaystyle {\ zacząć {wyrównany} \ ln q_ {\ mu} ^ {*} (\ mu) & = \ nazwa operatora {e} _ {\ tau} \ lewo [\ ln p (\ mathbf {X} \ mid \mu ,\tau )+\ln p(\mu \mid \tau )+\ln p(\tau )\right]+C\\&=\nazwa operatora {E} _{\tau }\left[\ln p(\mathbf {X} \mid \mu ,\tau )\right]+\nazwa operatora {E} _{\tau }\left[\ln p(\mu \mid \tau )\right]+\nazwa operatora { E} _{\tau }\left[\ln p(\tau )\right]+C\\&=\nazwa operatora {E} _{\tau }\left[\ln \prod _{n=1}^ {N}{\mathcal {N}}\left(x_{n}\mid \mu ,\tau ^{-1}\right)\right]+\operatorname {E} _{\tau }\left[\ ln {\mathcal {N}}\left(\mu \mid \mu _{0},(\lambda _{0}\tau )^{-1}\right)\right]+C_{2}\\ &=\operatorname {E} _{\tau }\left[\ln \prod _{n=1}^{N}{\sqrt {\frac {\tau }{2\pi }}}e^{- {\frac {(x_{n}-\mu )^{2}\tau }{2}}}\right]+\nazwa operatora {E} _{\tau }\left[\ln {\sqrt {\frac {\lambda _{0}\tau }{2\pi }}}e^{-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{ 2}}}\right]+C_{2}\\&=\nazwa operatora {E} _{\tau }\left[\sum _{n=1}^{N}\left({\frac {1} {2}}(\ln \tau -\ln 2\pi )-{\frac {(x_{n}-\mu )^{2}\tau }{2}}\rig ht)\right]+\nazwa operatora {E} _{\tau }\left[{\frac {1}{2}}(\ln \lambda _{0}+\ln \tau -\ln 2\pi ) -{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}\right]+C_{2}\\&=\nazwa operatora {E} _{\tau }\left[\sum _{n=1}^{N}-{\frac {(x_{n}-\mu )^{2}\tau }{2}}\right]+\ nazwa operatora {E} _{\tau }\left[-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\tau }{2}}\right]+\ nazwa operatora {E} _{\tau }\left[\sum _{n=1}^{N}{\frac {1}{2}}(\ln \tau -\ln 2\pi )\right]+ \operatorname {E} _{\tau }\left[{\frac {1}{2}}(\ln \lambda _{0}+\ln \tau -\ln 2\pi )\right]+C_{ 2}\\&=\nazwa operatora {E} _{\tau }\left[\sum _{n=1}^{N}-{\frac {(x_{n}-\mu )^{2}\ tau }{2}}\right]+\nazwa operatora {E} _{\tau }\left[-{\frac {(\mu -\mu _{0})^{2}\lambda _{0}\ tau }{2}}\right]+C_{3}\\&=-{\frac {\operatorname {E} _{\tau }[\tau ]}{2}}\left\{\sum _{ n=1}^{N}(x_{n}-\mu )^{2}+\lambda _{0}(\mu -\mu _{0})^{2}\right\}+C_{ 3}\end{wyrównany}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c64dbf7b78ed109532c4258d2f03ed35181be164)
W powyższej pochodnej, , i odnoszą się do wartości, które są stałe w zakresie . Zauważ, że termin nie jest funkcją i będzie miał taką samą wartość niezależnie od wartości . Stąd w wierszu 3 możemy na końcu wchłonąć to w wyraz stały. To samo robimy w wierszu 7.



![\nazwa operatora {E}_{{\tau }}[\ln p(\tau )]](https://wikimedia.org/api/rest_v1/media/math/render/svg/ccf212e8b1c0bdaf7c00735ff771c5f117572089)
Ostatni wiersz to po prostu wielomian kwadratowy w . Ponieważ jest to logarytm , możemy zobaczyć , że sam jest rozkładem Gaussa .

Z pewnej ilości żmudnej matematyki (rozszerzenie kwadraty wewnątrz szelki, rozdzielania i grupowania warunków obejmujących a i ukończenie kwadratowy over ), możemy czerpać parametry rozkładu Gaussa:

![\begin{align} \ln q_\mu^*(\mu) &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ \sum_{n=1 }^N (x_n-\mu)^2 + \lambda_0(\mu-\mu_0)^2 \right\} + C_3 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau ]}{2} \left\{ \sum_{n=1}^N (x_n^2-2x_n\mu + \mu^2) + \lambda_0(\mu^2-2\mu_0\mu + \mu_0^ 2) \right \} + C_3 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ \left(\sum_{n=1}^N x_n^2\right)-2\left(\sum_{n=1}^N x_n\right)\mu + \left ( \sum_{n=1}^N \mu^2 \right) + \lambda_0\ mu^2-2\lambda_0\mu_0\mu + \lambda_0\mu_0^2 \right\} + C_3 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\mu^2 -2\left(\lambda_0\mu_0 + \sum_{n=1}^N x_n\right)\mu + \left(\sum_{n=1} ^N x_n^2\right) + \lambda_0\mu_0^2 \right\} + C_3 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\ { (\lambda_0+N)\mu^2 -2\left(\lambda_0\mu_0 + \sum_{n=1}^N x_n\right)\mu \right\} + C_4 \\ &= -\frac{ \operatorname{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n= 1}^N x_n}{\lambda_0+N} \prawo )(\lambda_0+N) \mu \right\} + C_4 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N )\left(\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu\right) \right\} + C_4 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu^2 -2\left( \frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu + \left(\frac{\lambda_0\mu_0 + \sum_{n=1}^ N x_n}{\lambda_0+N}\right)^2 - \left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2\right ) \right\} + C_4 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau]}{2} \left\{ (\lambda_0+N)\left(\mu^2 -2\left(\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right) \mu + \left(\frac{\lambda_0\mu_0 + \sum_{ n=1}^N x_n}{\lambda_0+N}\right)^2 \right) \right\} + C_5 \\ &= -\frac{\nazwa operatora{E}_{\tau}[\tau] }{2} \left\{ (\lambda_0+N)\left(\mu-\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 \right\} + C_5 \\ &= -\frac{1}{2} (\lambda_0+N)\nazwa operatora{E}_{\tau}[\tau] \left(\mu -\frac{\lambda_0\mu_0 + \sum_{n=1}^N x_n}{\lambda_0+N}\right)^2 + C_5 \end{wyrównaj}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b95121a849ebbf25ba5413565ef4696267ba0e42)
Zauważ, że wszystkie powyższe kroki można skrócić, używając wzoru na sumę dwóch kwadratów .
Innymi słowy:
![{\ Displaystyle {\ zacząć {wyrównany} q_ {\ mu} ^ {*} (\ mu) i \ sim {\ mathcal {N}} (\ mu \ mid \ mu _ {N} \ lambda _ {N} ^{-1})\\\mu _{N}&={\frac {\lambda _{0}\mu _{0}+N{\bar {x}}}{\lambda _{0}+ N}}\\\lambda _{N}&=(\lambda _{0}+N)\nazwa operatora {E} _{\tau }[\tau ]\\{\bar {x}}&={\ frac {1}{N}}\sum _{n=1}^{N}x_{n}\end{wyrównany}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d299b83cbb420dff824c2914458942a0fb39859)
Wyprowadzenie q(τ)
Wyprowadzenie jest podobne do powyższego, chociaż pomijamy niektóre szczegóły ze względu na zwięzłość.

![\begin{align} \ln q_\tau^*(\tau) &= \operatorname{E}_{\mu}[\ln p(\mathbf{X}\mid \mu,\tau) + \ln p (\mu\mid \tau)] + \ln p(\tau) + \text{stała} \\ &= (a_0 - 1) \ln \tau - b_0 \tau + \frac{1}{2} \ ln \tau + \frac{N}{2} \ln \tau - \frac{\tau}{2} \nazwa operatora{E}_\mu \left [ \sum_{n=1}^N (x_n-\ mu)^2 + \lambda_0(\mu - \mu_0)^2 \right ] + \text{stała} \end{wyrównaj}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58986c8046658988c363da1009d0beedc83ce01c)
Potęgując obie strony, widzimy, że jest to rozkład gamma . Konkretnie:
![{\begin{aligned}q_{\tau }^{*}(\tau )&\sim \operatorname {Gamma}(\tau \mid a_{N},b_{N})\\a_{N}&= a_{0}+{\frac {N+1}{2}}\\b_{N}&=b_{0}+{\frac {1}{2}}\nazwa operatora {E}_{\mu } \left[\sum _{{n=1}}^{N}(x_{n}-\mu )^{2}+\lambda _{0}(\mu -\mu _{0})^{ 2}\right]\end{wyrównany}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6ca127beab48a5d09ca7e57f8826ed863d01727)
Algorytm obliczania parametrów
Podsumujmy wnioski z poprzednich rozdziałów:
oraz
W każdym przypadku parametry rozkładu po jednej ze zmiennych zależą od oczekiwań przyjętych względem drugiej zmiennej. Możemy rozszerzyć oczekiwania, korzystając ze standardowych wzorów na oczekiwania momentów rozkładu Gaussa i gamma:
![\begin{align} \operatorname{E}[\tau\mid a_N, b_N] &= \frac{a_N}{b_N} \\ \operatorname{E} \left [\mu\mid\mu_N,\lambda_N^{ -1} \right ] &= \mu_N \\ \operatorname{E}\left[X^2 \right] &= \operatorname{Var}(X) + (\operatorname{E}[X])^2 \ \ \operatorname{E} \left [\mu^2\mid\mu_N,\lambda_N^{-1} \right ] &= \lambda_N^{-1} + \mu_N^2 \end{align}](https://wikimedia.org/api/rest_v1/media/math/render/svg/917241f915e88f88f8e3ff74096507c6efe8551c)
Zastosowanie tych wzorów do powyższych równań jest w większości przypadków trywialne, ale równanie dla wymaga więcej pracy:

![\begin{align} b_N &= b_0 + \frac{1}{2} \operatorname{E}_\mu \left[\sum_{n=1}^N (x_n-\mu)^2 + \lambda_0( \mu - \mu_0)^2\right] \\ &= b_0 + \frac{1}{2} \nazwa operatora{E}_\mu \left[ (\lambda_0+N)\mu^2 -2 \left (\lambda_0\mu_0 + \sum_{n=1}^N x_n \right )\mu + \left(\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right] \\ &= b_0 + \frac{1}{2} \left[ (\lambda_0+N)\nazwa operatora{E}_\mu[\mu^2] -2 \left (\lambda_0\mu_0 + \sum_{ n=1}^N x_n \right)\nazwa operatora{E}_\mu [\mu] + \left (\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right ] \\ &= b_0 + \frac{1}{2} \left[ (\lambda_0+N) \left (\lambda_N^{-1} + \mu_N^2 \right ) -2 \left (\lambda_0\ mu_0 + \sum_{n=1}^N x_n \right)\mu_N + \left(\sum_{n=1}^N x_n^2 \right) + \lambda_0\mu_0^2 \right] \\ \end {wyrównywać}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16171a58ee7ad1a9dca35de3637f8034197b22a6)
Możemy wtedy zapisać równania parametrów w następujący sposób, bez żadnych oczekiwań:
![\begin{align} \mu_N &= \frac{\lambda_0 \mu_0 + N \bar{x}}{\lambda_0 + N} \\ \lambda_N &= (\lambda_0 + N) \frac{a_N}{b_N} \\ \bar{x} &= \frac{1}{N}\sum_{n=1}^N x_n \\ a_N &= a_0 + \frac{N+1}{2} \\ b_N &= b_0 + \frac{1}{2} \left[ (\lambda_0+N) \left (\lambda_N^{-1} + \mu_N^2 \right ) -2 \left (\lambda_0\mu_0 + \sum_{n =1}^N x_n \right )\mu_N + \left (\sum_{n=1}^N x_n^2 \right ) + \lambda_0\mu_0^2 \right] \end{align}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe12241932dc8dfb6a202e043b02cd60b3f593a6)
Zauważ, że między formułami dla i istnieją zależności cykliczne . To naturalnie sugeruje algorytm podobny do EM :

- Oblicz i użyj tych wartości do obliczenia i




- Zainicjuj do dowolnej wartości.
- Użyj bieżącej wartości wraz ze znanymi wartościami innych parametrów, aby obliczyć .

- Użyj bieżącej wartości wraz ze znanymi wartościami innych parametrów, aby obliczyć .

- Powtarzaj ostatnie dwa kroki aż do zbieżności (tj. dopóki żadna wartość nie zmieni się bardziej niż jakaś niewielka ilość).
Następnie mamy wartości hiperparametrów aproksymujących rozkładów parametrów a posteriori, których możemy użyć do obliczenia dowolnych właściwości a posteriori — np. jego średniej i wariancji, 95% obszaru o największej gęstości (najmniejszy przedział, który obejmuje 95 % całkowitego prawdopodobieństwa) itp.
Można wykazać, że ten algorytm gwarantuje zbieżność do lokalnego maksimum.
Należy również zauważyć, że rozkłady a posteriori mają taką samą formę jak odpowiadające im rozkłady wcześniejsze. Zrobiliśmy nie zakładamy tego; jedynym założeniem, jakie przyjęliśmy, było to, że rozkłady ulegają faktoryzacji, a forma rozkładów jest naturalna. Okazuje się (patrz niżej), że fakt, że rozkłady a posteriori mają taką samą postać jak rozkłady wcześniejsze, nie jest zbiegiem okoliczności, ale ogólnym wynikiem, gdy rozkłady poprzedzające należą do rodziny wykładniczej , co ma miejsce w większości przypadków standardowe dystrybucje.
Dalsza dyskusja
Przepis krok po kroku
Powyższy przykład pokazuje metodę, za pomocą której wyprowadza się aproksymację wariacyjną-bayesowską do gęstości prawdopodobieństwa a posteriori w danej sieci bayesowskiej :
- Opisz sieć za pomocą modelu graficznego , identyfikując zmienne obserwowane (dane) i zmienne nieobserwowane ( parametry i zmienne latentne ) oraz ich warunkowe rozkłady prawdopodobieństwa . Następnie Bayes konstruuje przybliżenie prawdopodobieństwa a posteriori . Aproksymacja ma podstawową właściwość, że jest rozkładem faktoryzowanym, tj. iloczynem dwóch lub więcej rozkładów niezależnych przez rozłączne podzbiory zmiennych nieobserwowanych.


- Podziel nieobserwowane zmienne na dwa lub więcej podzbiorów, z których zostaną wyprowadzone niezależne czynniki. Nie ma uniwersalnej procedury, aby to zrobić; tworzenie zbyt wielu podzbiorów daje słabe przybliżenie, podczas gdy tworzenie zbyt małej liczby sprawia, że cała wariacyjna procedura Bayesa jest niewykonalna. Zazwyczaj pierwszy podział polega na oddzieleniu parametrów i zmiennych ukrytych; często samo to wystarcza, aby uzyskać wykonalny wynik. Załóżmy, że partycje nazywają się .

- Dla danego podziału zapisz wzór na najlepszy rozkład aproksymujący, korzystając z równania podstawowego .
- Wypełnij wzór na łączny rozkład prawdopodobieństwa za pomocą modelu graficznego. Wszelkie rozkłady warunkowe składników, które nie obejmują żadnej ze zmiennych w, mogą zostać zignorowane; zostaną one złożone w stały termin.
- Uprość formułę i zastosuj operator oczekiwania, zgodnie z powyższym przykładem. Idealnie, powinno to uprościć oczekiwanie podstawowych funkcji zmiennych, których nie ma (np. pierwszy lub drugi surowy moment , oczekiwanie logarytmu itp.). Aby wariacyjna procedura Bayesa działała dobrze, oczekiwania te powinny być ogólnie wyrażalne analitycznie jako funkcje parametrów i/lub hiperparametrów rozkładów tych zmiennych. We wszystkich przypadkach te warunki oczekiwania są stałymi w odniesieniu do zmiennych w bieżącym podziale.
- Forma funkcjonalna wzoru w odniesieniu do zmiennych w aktualnym podziale wskazuje rodzaj rozkładu. W szczególności potęgowanie wzoru generuje funkcję gęstości prawdopodobieństwa (PDF) rozkładu (lub przynajmniej coś proporcjonalnego do niego, o nieznanej stałej normalizacji ). Aby cała metoda była wykonalna, powinno być możliwe rozpoznanie postaci funkcjonalnej jako należącej do znanego rozkładu. Konwersja formuły do postaci zgodnej z plikiem PDF o znanej dystrybucji może wymagać znacznych manipulacji matematycznych. Gdy jest to możliwe, stałą normalizacji można przywrócić z definicji, a równania parametrów znanego rozkładu można wyprowadzić przez wyodrębnienie odpowiednich części wzoru.
- Gdy wszystkie oczekiwania można zastąpić analitycznie funkcjami zmiennych spoza bieżącego podziału, a PDF umieścić w postaci umożliwiającej identyfikację ze znanym rozkładem, wynikiem jest zestaw równań wyrażających wartości optymalnych parametrów jako funkcje parametry zmiennych w innych przegrodach.
- Gdy tę procedurę można zastosować do wszystkich partycji, wynikiem jest zestaw wzajemnie powiązanych równań określających optymalne wartości wszystkich parametrów.
- Maksymalizację oczekiwań (EM) Procedura typ jest następnie nakładana, zbierając początkowej wartości dla każdego parametru oraz iteracja szeregu etapów, w których w każdym cyklu kroku poprzez równania, aktualizuje każdego parametru skrętu. Gwarantuje to zbieżność.
Najważniejsze punkty
Ze względu na wszystkie związane z tym manipulacje matematyczne, łatwo jest stracić orientację w dużym obrazie. Ważne rzeczy to:
- Ideą wariacyjnego Bayesa jest skonstruowanie analitycznego przybliżenia prawdopodobieństwa a posteriori zbioru zmiennych nieobserwowanych (parametry i zmienne latentne) na podstawie danych. Oznacza to, że forma rozwiązania jest podobna do innych metod wnioskowania bayesowskiego , takich jak próbkowanie Gibbsa — czyli rozkład, który stara się opisać wszystko, co wiadomo o zmiennych. Podobnie jak w innych metodach bayesowskich — ale inaczej niż np. w metodzie maksymalizacji oczekiwań (EM) lub innych metodach największej wiarygodności — oba typy zmiennych nieobserwowanych (tj. parametry i zmienne latentne) są traktowane tak samo, tj. jako zmienne losowe . Szacunki dla zmiennych można następnie wyprowadzić standardowymi metodami bayesowskimi, np. obliczając średnią rozkładu w celu uzyskania jednopunktowego oszacowania lub wyprowadzając wiarygodny przedział , region o największej gęstości itp.
- „Aproksymacja analityczna” oznacza, że można zapisać wzór na rozkład a posteriori. Formuła zazwyczaj składa się z iloczynu dobrze znanych rozkładów prawdopodobieństwa, z których każdy jest faktoryzowany przez zestaw nieobserwowanych zmiennych (tzn. jest warunkowo niezależny od innych zmiennych, biorąc pod uwagę obserwowane dane). Ten wzór nie jest prawdziwym rozkładem a posteriori, ale jego przybliżeniem; w szczególności, będzie na ogół dość ściśle zgadzał się w najniższych momentach nieobserwowanych zmiennych, np. średniej i wariancji .
- Wynikiem wszystkich manipulacji matematycznych jest (1) identyczność rozkładów prawdopodobieństwa składających się na czynniki oraz (2) wzajemnie zależne wzory na parametry tych rozkładów. Rzeczywiste wartości tych parametrów są obliczane numerycznie, poprzez naprzemienną procedurę iteracyjną, podobną do EM.
W porównaniu z maksymalizacją oczekiwań (EM)
Variation Bayes (VB) jest często porównywany z maksymalizacją oczekiwań (EM). Rzeczywista procedura numeryczna jest dość podobna, ponieważ obie są naprzemiennymi procedurami iteracyjnymi, które sukcesywnie zbliżają się do optymalnych wartości parametrów. Początkowe kroki w celu wyprowadzenia odpowiednich procedur są również niejasno podobne, oba zaczynają się od wzorów na gęstości prawdopodobieństwa i oba obejmują znaczne ilości manipulacji matematycznych.
Istnieje jednak szereg różnic. Najważniejsze jest to, co jest obliczane.
- EM oblicza estymatory punktowe rozkładu a posteriori tych zmiennych losowych, które można sklasyfikować jako „parametry”, ale tylko estymatory rzeczywistych rozkładów a posteriori zmiennych latentnych (przynajmniej w „miękkim EM”, a często tylko wtedy, gdy zmienne latentne są dyskretne ). Obliczone oceny punktowe są postaciami tych parametrów; brak innych informacji.
- Z drugiej strony VB oblicza oszacowania rzeczywistego rozkładu a posteriori wszystkich zmiennych, zarówno parametrów, jak i zmiennych latentnych. Gdy konieczne jest wyprowadzenie oszacowań punktowych, na ogół stosuje się średnią, a nie modę, jak jest to normalne we wnioskowaniu bayesowskim. W związku z tym parametry obliczone w VB nie mają takiego samego znaczenia jak te w EM. EM oblicza optymalne wartości parametrów samej sieci Bayesa. VB oblicza optymalne wartości parametrów rozkładów używanych do aproksymacji parametrów i zmiennych latentnych sieci Bayesa. Na przykład typowy model mieszaniny Gaussa będzie miał parametry dla średniej i wariancji każdego ze składników mieszaniny. EM bezpośrednio oszacowałoby optymalne wartości tych parametrów. Jednak VB najpierw dopasuje rozkład do tych parametrów — zazwyczaj w postaci wcześniejszego rozkładu , np. odwróconego rozkładu gamma o skali normalnej — a następnie obliczy wartości parametrów tego wcześniejszego rozkładu, tj. zasadniczo hiperparametrów . W tym przypadku VB obliczy optymalne oszacowania czterech parametrów odwróconego rozkładu gamma o skali normalnej, który opisuje łączny rozkład średniej i wariancji składnika.
Bardziej złożony przykład

Bayesowski model mieszaniny gaussowskiej z wykorzystaniem
notacji płytowej . Mniejsze kwadraty oznaczają stałe parametry; większe kółka oznaczają zmienne losowe. Wypełnione kształty wskazują znane wartości. Oznaczenie [K] oznacza wektor o rozmiarze
K ; [
D ,
D ] oznacza macierz o rozmiarze
D ×
D ;
Samo K oznacza
zmienną kategorialną z wynikami
K. Falista linia wychodząca od
z kończącego się poprzeczką wskazuje
przełącznik — wartość tej zmiennej wybiera dla innych przychodzących zmiennych, którą wartość użyć z tablicy size-
K możliwych wartości.
Wyobraźmy sobie model mieszanki bayesowskiej Gaussa opisany w następujący sposób:
![{\begin{wyrównany}{\mathbf {\pi }}&\sim \operatorname {SymDir}(K,\alpha _{0})\\{\mathbf {\Lambda }}_{{i=1\dots K}}&\sim {\mathcal {W}}({\mathbf {W}}_{0},\nu _{0})\\{\mathbf {\mu }}_{{i=1\ kropki K}}&\sim {\mathcal {N}}({\mathbf {\mu }}_{0},(\beta _{0}{\mathbf {\Lambda }}_{i})^{ {-1}})\\{\mathbf {z}}[i=1\dots N]&\sim \operatorname {Mult}(1,{\mathbf {\pi }})\\{\mathbf {x }}_{{i=1\dots N}}&\sim {\mathcal {N}}({\mathbf {\mu }}_{{z_{i}}},{{\mathbf {\Lambda } }_{{z_{i}}}}^{{-1}})\\K&={\text{liczba składników mieszających}}\\N&={\text{liczba punktów danych}}\end{ wyrównany}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e54f90a522209bd5e80751661fbd8f25570b952)
Notatka:
Interpretacja powyższych zmiennych jest następująca:
-
 to zbiór punktów danych, z których każdy jest wektorem dwuwymiarowym rozłożonym zgodnie z wielowymiarowym rozkładem Gaussa .
to zbiór punktów danych, z których każdy jest wektorem dwuwymiarowym rozłożonym zgodnie z wielowymiarowym rozkładem Gaussa .
-
 to zestaw zmiennych ukrytych, po jednej na punkt danych, określający, do którego składnika mieszaniny należy odpowiedni punkt danych, przy użyciu reprezentacji wektorowej „jeden z K” ze składnikami dla , jak opisano powyżej.
to zestaw zmiennych ukrytych, po jednej na punkt danych, określający, do którego składnika mieszaniny należy odpowiedni punkt danych, przy użyciu reprezentacji wektorowej „jeden z K” ze składnikami dla , jak opisano powyżej.

-
 to proporcje mieszania składników mieszanki.
to proporcje mieszania składników mieszanki.
-
 i określić parametry ( średnia i precyzja ) związane z każdym składnikiem mieszaniny.
i określić parametry ( średnia i precyzja ) związane z każdym składnikiem mieszaniny.
Wspólne prawdopodobieństwo wszystkich zmiennych można przepisać jako

gdzie znajdują się poszczególne czynniki

gdzie

Załóżmy, że .

Następnie
![{\begin{wyrównany}\ln q^{*}({\mathbf {Z}})&=\nazwa operatora {E}_{{{\mathbf {\pi }},{\mathbf {\mu }}, {\mathbf {\Lambda }}}}[\ln p({\mathbf {X}},{\mathbf {Z}},{\mathbf {\pi }},{\mathbf {\mu }},{ \mathbf {\Lambda }})]+{\text{stała}}\\&=\nazwa operatora {E}_{{{\mathbf {\pi }}}}[\ln p({\mathbf {Z} }\mid {\mathbf {\pi }})]+\operatorname {E}_{{{\mathbf {\mu }},{\mathbf {\Lambda }}}}[\ln p({\mathbf { X}}\mid {\mathbf {Z}},{\mathbf {\mu }},{\mathbf {\Lambda }})]+{\text{stała}}\\&=\sum _{{n =1}}^{N}\sum _{{k=1}}^{K}z_{{nk}}\ln \rho _{{nk}}+{\text{stała}}\end{wyrównana }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a9e6956e240ed7d5d347063c687111ca758eabfd)
gdzie zdefiniowaliśmy
![\ln \rho _{{nk}}=\nazwa operatora {E}[\ln \pi _{k}]+{\frac {1}{2}}\nazwa operatora {E}[\ln |{\mathbf { \Lambda }}_{k}|]-{\frac {D}{2}}\ln(2\pi )-{\frac {1}{2}}\nazwa operatora {E}_{{{\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}}}[({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k} )^{{{\rm {T}}}}{\mathbf {\Lambda }}_{k}({\mathbf {x}}_{n}-{\mathbf {\mu }}_{k} )]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6ec0788f8a16fa7e700c96d3af8382f54cbb287f)
Potęgowanie obu stron wzoru na plony


Wymaganie, aby to było znormalizowane, kończy się wymaganiem, aby suma równała się 1 po wszystkich wartościach , uzyskując



gdzie

Innymi słowy, jest iloczynem rozkładów wielomianowych z pojedynczą obserwacją , i współczynników nad każdą jednostką , który jest rozłożony jako rozkład wielomianowy z jedną obserwacją z parametrami dla .



Ponadto zauważamy, że
![\operatorname {E}[z_{{nk}}]=r_{{nk}}\,](https://wikimedia.org/api/rest_v1/media/math/render/svg/c15f150fa73aec952164769cfde73f6df58590e6)
co jest standardowym wynikiem dla rozkładów jakościowych.
Teraz, biorąc pod uwagę współczynnik , zauważ, że automatycznie uwzględnia się on ze względu na strukturę modelu graficznego definiującego nasz model mieszaniny Gaussa, który jest określony powyżej.


Następnie,
![{\begin{wyrównany}\ln q^{*}({\mathbf {\pi }})&=\ln p({\mathbf {\pi }})+\nazwa operatora {E}_{{{\mathbf {Z}}}}[\ln p({\mathbf {Z}}\mid {\mathbf {\pi }})]+{\text{stała}}\\&=(\alpha _{0}- 1)\sum _{{k=1}}^{K}\ln \pi _{k}+\sum _{{n=1}}^{N}\sum _{{k=1}}^ {K}r_{{nk}}\ln \pi _{k}+{\text{stała}}\end{wyrównana}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9ce937b397d56eb7f4ee329522f5ba5379abd69f)
Biorąc wykładnik obu stron, rozpoznajemy jako rozkład Dirichleta

gdzie

gdzie

Wreszcie
![\ln q^{*}({\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k})=\ln p({\mathbf {\mu }}_{k },{\mathbf {\Lambda }}_{k})+\sum _{{n=1}}^{N}\operatorname {E}[z_{{nk}}]\ln {\mathcal {N }}({\mathbf {x}}_{n}\mid {\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}^{{-1}})+ {\text{stała}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc21b5385915806fac7030e8de06621c21ee716c)
Grupowanie i odczytywanie terminów obejmujących i , wynikiem jest rozkład Gaussa-Wisharta podany przez



biorąc pod uwagę definicje

Wreszcie należy zauważyć, że te funkcje wymagają wartości , które sprawiają, że stosowanie , który jest zdefiniowany z kolei opiera się na , i . Teraz, gdy ustaliliśmy rozkłady, nad którymi brane są te oczekiwania, możemy wyprowadzić dla nich wzory:
![\nazwa operatora {E}[\ln \pi _{k}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/7038f8179432a3693f8296feacc5f8874ba6f267)
![\operatorname {E}[\ln |{\mathbf {\Lambda }}_{k}|]](https://wikimedia.org/api/rest_v1/media/math/render/svg/c07e1eecf8caee684700b0e4b63cc117051feab1)
![\operatorname {E}_{{{\mathbf {\mu }}_{k},{\mathbf {\Lambda }}_{k}}}[({\mathbf {x}}_{n}-{ \mathbf {\mu }}_{k})^{{{\rm {T}}}}{\mathbf {\Lambda }}_{k}({\mathbf {x}}_{n}-{ \mathbf {\mu }}_{k})]](https://wikimedia.org/api/rest_v1/media/math/render/svg/632ace27969c8d456caa65b802e8e8ce268e51bb)
![{\ Displaystyle {\ zacząć {wyrównany} \ nazwa operatora {E} _ {\ mathbf {\ mu} _ {k}, \ mathbf {\ Lambda} _ {k}} [(\ mathbf {x} _ {n} - \mathbf {\mu } _{k})^{\rm {T}}\mathbf {\Lambda } _{k}(\mathbf {x} _{n}-\mathbf {\mu } _{k} )]&=D\beta _{k}^{-1}+\nu _{k}(\mathbf {x} _{n}-\mathbf {m} _{k})^{\rm {T }}\mathbf {W} _{k}(\mathbf {x} _{n}-\mathbf {m} _{k})\\\ln {\widetilde {\Lambda }}_{k}&\ equiv \operatorname {E} [\ln |\mathbf {\Lambda } _{k}|]=\sum _{i=1}^{D}\psi \left({\frac {\nu _{k} +1-i}{2}}\right)+D\ln 2+\ln |\mathbf {W} _{k}|\\\ln {\widetilde {\pi }}_{k}&\equiv \operatorname {E} \left[\ln |\pi _{k}|\right]=\psi (\alpha _{k})-\psi \left(\sum _{i=1}^{K} \alpha _{i}\right)\end{wyrównany}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef9311bd1332799fbb4578b2547cd94b56b37acd)
Wyniki te prowadzą do

Można je przekonwertować z wartości proporcjonalnych na bezwzględne, normalizując, tak aby odpowiednie wartości sumowały się do 1.
Zwróć uwagę, że:
- Równania aktualizacji parametrów , , oraz zmiennych i zależą od statystyk , , i , a te statystyki z kolei zależą od .







- Równania aktualizacji parametrów zmiennej zależą od statystyki , która z kolei zależy od .

- Równanie aktualizacji dla ma bezpośrednią zależność kołową od , , a także pośrednią zależność kołową od , oraz przez i .


Sugeruje to procedurę iteracyjną, która zmienia się między dwoma krokami:
- Krok E, który oblicza wartość przy użyciu bieżących wartości wszystkich innych parametrów.
- Krok M, który używa nowej wartości do obliczenia nowych wartości wszystkich pozostałych parametrów.
Należy zauważyć, że te kroki ściśle odpowiadają standardowemu algorytmowi EM w celu uzyskania rozwiązania maksymalnego prawdopodobieństwa lub maksimum a posteriori (MAP) dla parametrów modelu mieszaniny Gaussa . Odpowiedzialność w kroku E ściśle odpowiada prawdopodobieństwu a posteriori ukrytych zmiennych danych, tj. ; obliczanie statystyk , i odpowiada ściśle obliczaniu odpowiednich statystyk „miękkiego liczenia” na danych; a wykorzystanie tych statystyk do obliczenia nowych wartości parametrów odpowiada ściśle wykorzystaniu miękkich zliczeń do obliczenia nowych wartości parametrów w normalnym EM w modelu mieszaniny Gaussa.

Rozkłady wykładniczo-rodzinne
Należy zauważyć, że w poprzednim przykładzie, po założeniu, że rozkład względem nieobserwowanych zmiennych zostanie rozłożony na rozkłady względem „parametrów” i rozkładów względem „danych ukrytych”, pochodny „najlepszy” rozkład dla każdej zmiennej należał do tej samej rodziny, co odpowiednia wcześniejszy rozkład nad zmienną. Jest to ogólny wynik, który jest prawdziwy dla wszystkich wcześniejszych rozkładów pochodzących z rodziny wykładniczej .
Zobacz też
Uwagi
Bibliografia
Zewnętrzne linki
-
Podręcznik on-line: Information Theory, Inference, and Learning Algorithms , autorstwa Davida JC MacKaya, stanowi wprowadzenie do metod wariacyjnych (s. 422).
-
Samouczek dotyczący Bayesa wariacyjnego . Fox, C. i Roberts, S. 2012. Przegląd sztucznej inteligencji, doi : 10.1007/s10462-011-9236-8 .
-
Variational-Bayes Repository Repozytorium artykułów naukowych, oprogramowania i linków związanych z wykorzystaniem metod wariacyjnych do przybliżonego uczenia bayesowskiego do 2003 roku.
-
Algorytmy wariacyjne dla przybliżonego wnioskowania bayesowskiego , autorstwa MJ Beala, zawierają porównania EM z zmiennością bayesowską EM i wyprowadzenia kilku modeli, w tym wariacyjnych bayesowskich HMM.
-
Wyjaśnienie wysokiego poziomu wnioskowania wariacyjnego autorstwa Jasona Eisnera może być warte przeczytania przed bardziej szczegółowym matematycznym omówieniem.
-
Copula Variational Bayes inference via information geometry (pdf) Tran, VH 2018. Ten artykuł jest przeznaczony głównie dla studentów. Poprzez dywergencję Bregmana artykuł pokazuje, że Variational Bayes jest po prostu uogólnioną pitagorejską projekcją prawdziwego modelu na dowolnie skorelowaną (kopulę) przestrzeń dystrybucyjną, której niezależna przestrzeń jest jedynie szczególnym przypadkiem.






