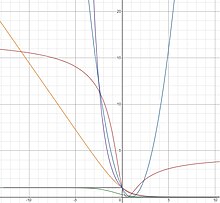
Stałe funkcje strat Bayesa: strata zero-jedynkowa (szara), strata okrutna (zielona), strata logistyczna (pomarańczowa), strata wykładnicza (fioletowa), strata styczna (brązowa), strata kwadratowa (niebieska)
W uczenia maszynowego i optymalizacji matematycznej , funkcje strat dla klasyfikacji są wykonalne obliczeniowo funkcji strat reprezentujące cenę zapłaconą za niedokładności w przewidywaniach problemów klasyfikacyjnych (problemy identyfikacji jakiej kategorii należy dana obserwacja to). Biorąc pod uwagę przestrzeń wszystkich możliwych danych wejściowych (zwykle ) i zbiór etykiet (możliwych wyników), typowym celem algorytmów klasyfikacji jest znalezienie funkcji, która najlepiej przewiduje etykietę dla danego wejścia . Jednak ze względu na niekompletne informacje, szum w pomiarze lub probabilistyczne składniki w procesie bazowym, możliwe jest, że to samo wygeneruje inne . W rezultacie celem problemu uczenia się jest zminimalizowanie oczekiwanej straty (znanej również jako ryzyko), zdefiniowanej jako






![{\ Displaystyle I [f] = \ Displaystyle \ int _ {{\ mathcal {X}} \ razy {\ mathcal {Y}}} V (f ({\ vec {x}}), r) p ({\ vec {x}}, y) \, d {\ vec {x}} \, dy}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a681d2ec2b4e729a58045cd58dd718b1cc91b3d6)
gdzie jest daną funkcją straty i jest funkcją gęstości prawdopodobieństwa procesu, który wygenerował dane, którą można równoważnie zapisać jako



W ramach klasyfikacji kilka powszechnie używanych funkcji strat jest zapisanych wyłącznie w odniesieniu do produktu prawdziwej etykiety i przewidywanej etykiety . Dlatego można je zdefiniować jako funkcje tylko jednej zmiennej , a więc o odpowiednio dobranej funkcji . Są to tak zwane funkcje strat oparte na marży . Wybór funkcji straty opartej na marży sprowadza się do wyboru . Wybór funkcji straty w tych ramach wpływa na optymalny, który minimalizuje oczekiwane ryzyko.






W przypadku klasyfikacji binarnej możliwe jest uproszczenie obliczania oczekiwanego ryzyka z całki określonej powyżej. Konkretnie,
![{\ Displaystyle {\ rozpocząć {wyrównane} ja [f] & = \ int _ {{\ mathcal {X}} \ razy {\ mathcal {Y}}} V (f ({\ vec {x}}), y ) p ({\ vec {x}}, y) \, d {\ vec {x}} \, dy \\ [6pt] & = \ int _ {\ mathcal {X}} \ int _ {\ mathcal {{ Y}} \ phi (yf ({\ vec {x}})) p (y \ mid {\ vec {x}}) p ({\ vec {x}}) \, dy \, d {\ vec { x}} \\ [6pt] & = \ int _ {\ mathcal {X}} [\ phi (f ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) p (-1 \ mid {\ vec {x}})] p ({\ vec {x}}) \, d {\ vec {x}} \ \ [6pt] & = \ int _ {\ mathcal {X}} [\ phi (f ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) (1-p (1 \ mid {\ vec {x}}))] p ({\ vec {x}}) \, d {\ vec {x}} \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b790a75d49d31c4d0b845445046bae07114894ee)
Druga równość wynika z właściwości opisanych powyżej. Trzecia równość wynika z faktu, że 1 i −1 są jedynymi możliwymi wartościami dla , a czwarta ponieważ . Termin w nawiasach nazywany jest ryzykiem warunkowym.
![{\ Displaystyle [\ phi (f ({\ vec {x}})) p (1 \ mid {\ vec {x}}) + \ phi (-f ({\ vec {x}})) (1- p (1 \ mid {\ vec {x}}))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/976cb6e601d74f6154999611a9c8113ee189b6c4)
Można rozwiązać minimalizator , biorąc pochodną funkcjonalną ostatniej równości względem i ustawiając pochodną równą 0. Wynikiem tego będzie następujące równanie
![Gdyby]](https://wikimedia.org/api/rest_v1/media/math/render/svg/8213b3ec4b7c34969992d3f12dd96b830c9082ef)


co jest równoznaczne z ustawieniem pochodnej ryzyka warunkowego na zero.
Biorąc pod uwagę binarny charakter klasyfikacji, dobór naturalny dla funkcji straty (zakładając równy koszt dla fałszywie dodatnich i fałszywie ujemnych ) byłby funkcją straty 0-1 ( funkcja wskaźnika 0-1 ), która przyjmuje wartość 0, jeśli klasyfikacja jest równa klasie prawdziwej lub 1, jeśli przewidywana klasyfikacja nie jest zgodna z klasą prawdziwą. Ten wybór jest wzorowany przez

gdzie wskazuje funkcję krokową Heaviside . Jednak ta funkcja straty nie jest wypukła i nie jest gładka, a rozwiązanie optymalnego rozwiązania jest NP-trudnym problemem optymalizacji kombinatorycznej. W rezultacie lepiej jest zastąpić powszechnie stosowane algorytmy uczące się substytutami funkcji straty, które są podatne na traktowanie, ponieważ mają one dogodne właściwości, takie jak wypukłość i gładkość. Oprócz ich obliczeniowej wykonalności można wykazać, że rozwiązania problemu uczenia się przy użyciu tych surogatów straty pozwalają na przywrócenie rzeczywistego rozwiązania pierwotnego problemu klasyfikacyjnego. Niektóre z tych surogatów opisano poniżej.

W praktyce rozkład prawdopodobieństwa jest nieznany. W konsekwencji, wykorzystanie zestawu uczącego składającego się z niezależnie i identycznie rozmieszczonych punktów próbkowania


czerpany z przestrzeni próbkowania danych , dąży się do zminimalizowania ryzyka empirycznego
![{\ Displaystyle I_ {S} [f] = {\ Frac {1} {n}} \ suma _ {i = 1} ^ {n} V (f ({\ vec {x}} _ {i}), y_ {i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f11407df44b1dc610c3fe193ce436cc33520ffe5)
jako wskaźnik zastępczy oczekiwanego ryzyka. ( Bardziej szczegółowy opis można znaleźć w statystycznej teorii uczenia się).
Konsystencja Bayesa
Korzystając z twierdzenia Bayesa , można wykazać, że optymalna , tj. Taka, która minimalizuje oczekiwane ryzyko związane ze stratą zero-jedynkową, realizuje regułę decyzji optymalnej Bayesa dla problemu klasyfikacji binarnej i ma postać

-
 .
.
Mówi się, że funkcja straty jest skalibrowana klasyfikacyjnie lub spójna Bayesa, jeśli jej optymalna wartość jest taka, a zatem jest optymalna zgodnie z regułą decyzyjną Bayesa. Funkcja spójnej straty Bayesa pozwala nam znaleźć optymalną funkcję decyzyjną Bayesa poprzez bezpośrednią minimalizację oczekiwanego ryzyka i bez konieczności jawnego modelowania funkcji gęstości prawdopodobieństwa.

W przypadku wypukłej straty marginesu można wykazać, że Bayes jest spójny wtedy i tylko wtedy, gdy jest różniczkowalny przy 0 i . Jednak wynik ten nie wyklucza istnienia nie wypukłych spójnych funkcji straty Bayesa. Bardziej ogólny wynik stwierdza, że spójne funkcje strat Bayesa można wygenerować przy użyciu następującego sformułowania


-
![{\ Displaystyle \ phi (v) = do [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] \; \; \; \; \; (2)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ba1d9d0d51b1c65272af55aa780a285afa90d9d) ,
,
gdzie jakikolwiek odwracalna funkcja tak, że a jest każdy różniczkowalną funkcją ściśle wklęsła, tak że . Tabela-I pokazuje wygenerowane spójne funkcje strat Bayesa dla niektórych przykładowych wyborów i . Zwróć uwagę, że straty Savage i Tangent nie są wypukłe. Okazało się, że takie nie wypukłe funkcje straty są przydatne w przypadku wartości odstających w klasyfikacji. Dla wszystkich funkcji strat generowanych z (2), prawdopodobieństwo późniejsze można znaleźć za pomocą funkcji odwracalnego łącza jako . Takie funkcje straty, w których prawdopodobieństwo a posteriori można odzyskać za pomocą połączenia odwracalnego, nazywane są właściwymi funkcjami straty .







Tabela-I
| Nazwa straty
|

|
|
|

|
| Wykładniczy
|

|

|

|

|
| Logistyka
|

|
![{\ Displaystyle {\ Frac {1} {\ log (2)}} [- \ eta \ log (\ eta) - (1- \ eta) \ log (1- \ eta)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e609e1c16646f7a8a99eb51b64fb94416a6a425)
|

|

|
| Kwadrat
|

|

|

|

|
| Brutalny
|

|

|
|
|
| Tangens
|

|
|

|

|
Jedyny minimalizator oczekiwanego ryzyka, związany z powyższymi wygenerowanymi funkcjami straty, można znaleźć bezpośrednio z równania (1) i wykazać, że jest równy odpowiadającemu . Dotyczy to nawet funkcji strat, które nie są wypukłe, co oznacza, że algorytmy oparte na spadku gradientu, takie jak wzmocnienie gradientu, mogą być użyte do skonstruowania minimalizatora.
Właściwe funkcje straty, margines straty i regularyzacja
Aby zapewnić prawidłowe funkcje straty, margines straty można zdefiniować jako i wykazać, że jest bezpośrednio powiązany z właściwościami regularyzacji klasyfikatora. W szczególności funkcja straty większego marginesu zwiększa regularyzację i daje lepsze oszacowania późniejszego prawdopodobieństwa. Na przykład, margines straty może zostać zwiększony dla straty logistycznej poprzez wprowadzenie parametru i zapisanie straty logistycznej, gdzie mniejszy, zwiększa margines straty. Wykazano, że jest to bezpośrednio równoważne ze zmniejszeniem szybkości uczenia się przy wzmocnieniu gradientu, gdzie zmniejszenie poprawia regularyzację wzmacnianego klasyfikatora. Teoria wyjaśnia, że kiedy stosuje się współczynnik uczenia się , prawidłowy wzór na obliczenie późniejszego prawdopodobieństwa to teraz .






Podsumowując, wybierając funkcję straty z większym marginesem (mniejszym ) zwiększamy regularyzację i poprawiamy nasze oszacowania prawdopodobieństwa późniejszego, co z kolei poprawia krzywą ROC końcowego klasyfikatora.
Kwadratowa strata
Chociaż jest częściej używana w regresji, kwadratowa funkcja straty może zostać ponownie zapisana jako funkcja i wykorzystana do klasyfikacji. Można go wygenerować za pomocą (2) i tabeli-I w następujący sposób

![{\ Displaystyle \ phi (v) = do [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = 4 ({\ frac {1} {2}} (v + 1)) (1 - {\ frac {1} {2}} (v + 1)) + (1 - {\ frac {1} {2}} (v + 1)) (4-8 ({\ frac {1} {2}} (v + 1))) = (1-v) ^ {2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7cdde8f62987c985c1028a98d8c24682dfe0c2d7)
Kwadratowa funkcja strat jest zarówno wypukła, jak i gładka. Jednak kwadratowa funkcja straty ma tendencję do nadmiernego karania wartości odstających, prowadząc do wolniejszych współczynników zbieżności (w odniesieniu do złożoności próbki) niż w przypadku funkcji straty logistycznej lub straty zawiasowej. Ponadto funkcje, które dają wysokie wartości dla niektórych, będą źle działać z kwadratową funkcją straty, ponieważ wysokie wartości będą surowo karane, niezależnie od tego, czy znaki i zgodność.


Zaletą kwadratowej funkcji straty jest to, że jej struktura umożliwia łatwe sprawdzanie krzyżowe parametrów regularyzacji. W szczególności dla regularyzacji Tichonowa , można rozwiązać parametr regularyzacji za pomocą walidacji krzyżowej pominąć jeden na zewnątrz w tym samym czasie, jaki byłby potrzebny do rozwiązania pojedynczego problemu.
Minimalizator funkcji strat kwadratowych można znaleźć bezpośrednio z równania (1) jako

Strata logistyczna
Funkcję straty logistycznej można wygenerować za pomocą (2) i tabeli-I w następujący sposób
![{\ Displaystyle {\ rozpocząć {wyrównane} \ phi (v) & = do [f ^ {- 1} (v)] + \ lewo (1-f ^ {- 1} (v) \ prawej) \, C ' \ left [f ^ {- 1} (v) \ right] \\ & = {\ frac {1} {\ log (2)}} \ left [{\ frac {-e ^ {v}} {1+ e ^ {v}}} \ log {\ frac {e ^ {v}} {1 + e ^ {v}}} - \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ log \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ right] + \ left (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}} \ right) \ left [{\ frac {-1} {\ log (2)}} \ log \ left ({\ frac {\ frac { e ^ {v}} {1 + e ^ {v}}} {1 - {\ frac {e ^ {v}} {1 + e ^ {v}}}}} \ right) \ right] \\ & = {\ frac {1} {\ log (2)}} \ log (1 + e ^ {- v}). \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4fd7a4c1188c935bcf5f76e4063f97034fb54e39)
Strata logistyczna jest wypukła i rośnie liniowo dla wartości ujemnych, co czyni ją mniej wrażliwą na wartości odstające. Strata logistyczna jest wykorzystywana w algorytmie LogitBoost .
Minimalizator funkcji straty logistycznej można znaleźć bezpośrednio z równania (1) jako

Ta funkcja jest niezdefiniowana, gdy lub (zmierza odpowiednio w kierunku ∞ i −∞), ale przewiduje gładką krzywą, która rośnie wraz ze wzrostem i równa się 0, gdy .




Łatwo jest sprawdzić, czy strata logistyczna i binarna strata entropii krzyżowej (strata logów) są w rzeczywistości takie same (aż do stałej multiplikatywnej ). Utrata entropii krzyżowej jest ściśle związana z dywergencją Kullbacka-Leiblera między rozkładem empirycznym a rozkładem przewidywanym. Utrata entropii krzyżowej jest wszechobecna we współczesnych głębokich sieciach neuronowych .

Strata wykładnicza
Wykładniczą funkcję straty można wygenerować za pomocą (2) i tabeli-I w następujący sposób
![{\ Displaystyle \ phi (v) = do [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = 2 {\ sqrt {({\ frac {e ^ {2v}} {1 + e ^ {2v}}}) (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v}}}) }} + (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v}}}) ({\ frac {1 - {\ frac {2e ^ {2v}} {1 + e ^ { 2v}}}} {\ sqrt {{\ frac {e ^ {2v}} {1 + e ^ {2v}}} (1 - {\ frac {e ^ {2v}} {1 + e ^ {2v} }})}}}) = e ^ {- v}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aaf52f9ceb280f470317e416a711b1e924cc1bd0)
Strata wykładnicza jest wypukła i rośnie wykładniczo dla wartości ujemnych, co czyni ją bardziej wrażliwą na wartości odstające. W algorytmie AdaBoost wykorzystywana jest wykładnicza strata .
Minimalizator funkcji wykładniczej straty można znaleźć bezpośrednio z równania (1) jako

Dzika strata
Stratę Savage można wygenerować za pomocą (2) i Tabeli-I w następujący sposób
![{\ Displaystyle \ phi (v) = do [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1} (v)] = ( {\ frac {e ^ {v}} {1 + e ^ {v}}}) (1 - {\ frac {e ^ {v}} {1 + e ^ {v}}}) + (1- { \ frac {e ^ {v}} {1 + e ^ {v}}}) (1 - {\ frac {2e ^ {v}} {1 + e ^ {v}}}) = {\ frac {1 } {(1 + e ^ {v}) ^ {2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3bc29f01f367ef3f4d6f92ce2f91827622a59b30)
Strata Savage jest quasi-wypukła i ograniczona do dużych wartości ujemnych, co czyni ją mniej wrażliwą na wartości odstające. Strata Savage została wykorzystana do wzmocnienia gradientu i algorytmu SavageBoost.
Minimalizator dla funkcji straty Savage'a można znaleźć bezpośrednio z równania (1) jako

Strata styczna
Stratę styczną można wygenerować za pomocą (2) i tabeli-I w następujący sposób
![{\ Displaystyle {\ zaczynać {wyrównane} \ phi (v) & = do [f ^ {- 1} (v)] + (1-f ^ {- 1} (v)) C '[f ^ {- 1 } (v)] = 4 (\ arctan (v) + {\ frac {1} {2}}) (1 - (\ arctan (v) + {\ frac {1} {2}})) + (1 - (\ arctan (v) + {\ frac {1} {2}})) (4-8 (\ arctan (v) + {\ frac {1} {2}})) \\ & = (2 \ arctan (v) -1) ^ {2}. \ end {aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/48fc53108e779ecf1e26b0725b3873944fcd9644)
Utrata styczna jest quasi-wypukła i ograniczona do dużych wartości ujemnych, co czyni ją mniej wrażliwą na wartości odstające. Co ciekawe, utrata styczna nakłada również ograniczoną karę na punkty danych, które zostały sklasyfikowane „zbyt poprawnie”. Może to pomóc w zapobieganiu przetrenowaniu zbioru danych. Utrata styczna została wykorzystana we wzmocnieniu gradientowym , algorytmie TangentBoost i naprzemiennych lasach decyzyjnych.
Minimalizator funkcji straty styczności można znaleźć bezpośrednio z równania (1) jako

Utrata zawiasów
Funkcja utraty zawiasów jest definiowana za pomocą , gdzie jest dodatnią funkcją części .
![{\ Displaystyle \ phi (\ upsilon) = \ max (0,1- \ upsilon) = [1- \ upsilon] _ {+}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/068b33990cb9f189f89c1c4b775424ff8bd5fade)
![{\ displaystyle [a] _ {+} = \ max (0, a)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eb205e8d8fd29396410d5c3764b95f1323335f6e)
![{\ Displaystyle V (f ({\ vec {x}}), r) = \ max (0,1-yf ({\ vec {x}})) = [1-yf ({\ vec {x}} )] _ {+}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bec5bd9d55a0fa201d877181b995db28b17f9827)
Utrata zawiasu zapewnia stosunkowo ciasną, wypukłą górną granicę funkcji wskaźnika 0–1 . W szczególności utrata zawiasu jest równa funkcji wskaźnika 0–1, kiedy i . Ponadto empiryczna minimalizacja ryzyka tej straty jest równoważna klasycznemu sformułowaniu dla maszyn wektorów nośnych (SVM). Prawidłowo sklasyfikowane punkty leżące poza granicami marginesu wektorów nośnych nie są karane, natomiast punkty w granicach marginesu lub po niewłaściwej stronie hiperpłaszczyzny są karane liniowo w stosunku do ich odległości od właściwej granicy.


Chociaż funkcja utraty zawiasów jest zarówno wypukła, jak i ciągła, nie jest ona gładka (nie jest różniczkowalna) przy . W związku z tym utraty funkcji zawiasy nie mogą być używane z największego spadku metod lub stochastycznych największego spadku sposoby, które opierają się na różniczkowalności na całej domeny. Jednak utrata zawiasu ma subgradient w , co pozwala na wykorzystanie metod obniżania subgradient . SVM wykorzystujące funkcję utraty zawiasów można również rozwiązać za pomocą programowania kwadratowego .

Minimalizatorem dla funkcji utraty zawiasów jest

kiedy , co odpowiada funkcji wskaźnika 0–1. Ten wniosek sprawia, że utrata zawiasu jest dość atrakcyjna, ponieważ można postawić granice różnicy między oczekiwanym ryzykiem a oznaką funkcji utraty zawiasu. Utrata zawiasu nie może pochodzić z (2), ponieważ nie jest odwracalna.


Uogólniona gładka utrata zawiasów
Uogólniona funkcja gładkiej utraty zawiasu z parametrem jest zdefiniowana jako


gdzie

Zwiększa się monotonicznie i osiąga 0, kiedy .

Zobacz też
Bibliografia




