
Estymacja zmiennych instrumentalnych - Instrumental variables estimation
W statystyce , ekonometrii , epidemiologii i dyscyplinach pokrewnych, metoda zmiennych instrumentalnych ( IV ) jest wykorzystywana do szacowania związków przyczynowych, gdy kontrolowane eksperymenty nie są wykonalne lub gdy leczenie nie jest skutecznie dostarczane do każdej jednostki w randomizowanym eksperymencie. Intuicyjnie, IV są używane, gdy zmienna objaśniająca będąca przedmiotem zainteresowania jest skorelowana z terminem błędu, w którym to przypadku zwykłe najmniejszych kwadratów i ANOVA dają wyniki obciążone . Prawidłowy instrument indukuje zmiany w zmiennej objaśniającej, ale nie ma niezależnego wpływu na zmienną zależną, pozwalając badaczowi odkryć przyczynowy wpływ zmiennej objaśniającej na zmienną zależną.
Metody zmiennych instrumentalnych pozwalają na spójną estymację, gdy zmienne objaśniające (zmienne towarzyszące) są skorelowane z warunkami błędu w modelu regresji . Taka korelacja może wystąpić, gdy:
- zmiany zmiennej zależnej zmieniają wartość przynajmniej jednej ze zmiennych towarzyszących (przyczynowość „odwrócona”),
- są pominięte zmienne , które wpływają zarówno na zmienne zależne i niezależne, lub
- te zmienne podlegają nieprzypadkowy błędu pomiarowego .
Zmienne objaśniające, które cierpią z powodu jednego lub więcej z tych problemów w kontekście regresji, są czasami określane jako endogeniczne . W tej sytuacji zwykłe metody najmniejszych kwadratów dają tendencyjne i niespójne szacunki. Jeśli jednak instrument jest dostępny, nadal można uzyskać spójne szacunki. Instrument jest zmienną, która sama nie należy do równania objaśniającego, ale jest skorelowana z endogenicznymi zmiennymi objaśniającymi, warunkowo od wartości innych zmiennych towarzyszących.
W modelach liniowych istnieją dwa główne wymagania dotyczące używania IV:
- Instrument musi być skorelowany z endogenicznymi zmiennymi objaśniającymi, warunkowo z innymi współzmiennymi. Jeśli ta korelacja jest silna, mówi się, że instrument ma silny pierwszy etap . Słaba korelacja może dostarczać mylących wniosków dotyczących oszacowań parametrów i błędów standardowych.
- Instrument nie może być skorelowany z członem błędu w równaniu objaśniającym, w zależności od innych zmiennych towarzyszących. Innymi słowy, instrument nie może cierpieć z powodu tego samego problemu, co pierwotna zmienna predykcyjna. Jeśli ten warunek jest spełniony, mówi się, że instrument spełnia ograniczenie wykluczenia .
Wstęp
Pojęcie zmiennych instrumentalnych zostało po raz pierwszy wyprowadzone przez Philipa G. Wrighta , prawdopodobnie we współautorstwie z jego synem Sewallem Wrightem , w kontekście równoczesnych równań w jego książce z 1928 r. Taryfa na oleje zwierzęce i roślinne . W 1945 roku Olav Reiersøl zastosował to samo podejście w kontekście modeli błędów w zmiennych w swojej dysertacji, nadając metodzie jej nazwę.
Chociaż idee stojące za IV rozciągają się na szeroką klasę modeli, bardzo powszechnym kontekstem IV jest regresja liniowa. Tradycyjnie zmienną instrumentalną definiuje się jako zmienną Z, która jest skorelowana ze zmienną niezależną X i nieskorelowana z „okresem błędu” U w równaniu liniowym

jest wektorem. jest macierzą, zwykle z kolumną jedynek i być może z dodatkowymi kolumnami dla innych zmiennych towarzyszących. Zastanów się, jak instrument pozwala na odzyskanie. Przypomnijmy, że OLS rozwiązuje w taki sposób, że (kiedy zminimalizować sumę kwadratu błędów, warunek pierwszego rzędu jest dokładnie ). Jeśli prawda model jest Uważa się, że ze względu na którąkolwiek z wyżej wymienionych powodów, na przykład, jeśli istnieje pominięte zmienne , które ma wpływ zarówno na i oddzielnie wówczas OLS procedura nie otrzymano przyczynowy wpływ na . OLS po prostu wybierze parametr, który powoduje, że powstałe błędy wydają się nieskorelowane z .








Rozważ dla uproszczenia przypadek jednej zmiennej. Załóżmy, że rozważamy regresję z jedną zmienną i stałą (być może żadne inne współzmienne nie są potrzebne, a może podzieliliśmy na części inne istotne współzmienne):

W tym przypadku współczynnik regresora będącego przedmiotem zainteresowania jest podany przez . Zastępując daje


![{\ Displaystyle {\ zacząć {wyrównany} {\ widehat {\ beta}} i = {\ Frac {\ Operator {cov} (x, y)} {\ Operator {var} (x)}} = {\ Frac { \operatorname {cov} (x,\alpha +\beta x+u)}{\operatorname {var} (x)}}\\[6pt]&={\frac {\operatorname {cov} (x,\alpha +\beta x)}{\nazwa operatora {zmienna} (x)}}+{\frac {\nazwa operatora {cov} (x,u)}{\nazwa operatora {zmienna} (x)}}=\beta ^{* }+{\frac {\nazwa operatora {cov} (x,u)}{\nazwa operatora {zmienna} (x)}},\end{wyrównany}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0fa71a1544a7e0714dae657ee944feb5cc4a02a)
gdzie jest jaki byłby szacowany wektor współczynnika, gdyby x nie było skorelowane z u . W tym przypadku można wykazać, że jest to bezstronny estymator If w podstawowym modelu, w który wierzymy, a następnie OLS daje współczynnik, który nie odzwierciedla podstawowego efektu przyczynowego zainteresowania. IV pomaga rozwiązać ten problem, identyfikując parametry nie na podstawie tego, czy jest nieskorelowana z , ale na podstawie tego, czy inna zmienna jest nieskorelowana z . Jeśli teoria sugeruje, że jest to związane z (pierwszy etap), ale nieskorelowane z (ograniczeniem wykluczenia), wówczas IV może zidentyfikować interesujący parametr przyczynowy, w którym OLS zawodzi. Ponieważ istnieje wiele konkretnych sposobów używania i wyprowadzania estymatorów IV, nawet w przypadku liniowym (IV, 2SLS, GMM), zachowujemy dalszą dyskusję w sekcji Estymacja poniżej.







Przykład
Nieformalnie, próbując oszacować przyczynowy wpływ jakiejś zmiennej X na inną Y , instrumentem jest trzecia zmienna Z, która wpływa na Y tylko poprzez swój wpływ na X . Załóżmy na przykład, że naukowiec chce oszacować przyczynowy wpływ palenia na ogólny stan zdrowia. Korelacja między zdrowiem a paleniem nie oznacza, że palenie powoduje zły stan zdrowia, ponieważ inne zmienne, takie jak depresja, mogą wpływać zarówno na zdrowie, jak i na palenie, lub ponieważ zdrowie może wpływać na palenie. Przeprowadzanie kontrolowanych eksperymentów dotyczących palenia w populacji ogólnej jest w najlepszym razie trudne i kosztowne. Badacz może podjąć próbę oszacowania przyczynowego wpływu palenia na zdrowie na podstawie danych obserwacyjnych, wykorzystując jako instrument palenia stawkę podatku od wyrobów tytoniowych. Stawka podatku od wyrobów tytoniowych jest rozsądnym wyborem instrumentu, ponieważ badacz wychodzi z założenia, że można ją skorelować ze zdrowiem jedynie poprzez jej wpływ na palenie. Jeśli badacz następnie stwierdzi, że podatki od tytoniu i stan zdrowia są ze sobą skorelowane, można to uznać za dowód na to, że palenie powoduje zmiany w stanie zdrowia.
Angrist i Krueger (2001) przedstawiają przegląd historii i zastosowań technik zmiennych instrumentalnych.
Definicja graficzna
Oczywiście techniki IV zostały opracowane wśród znacznie szerszej klasy modeli nieliniowych. Ogólne definicje zmiennych instrumentalnych, wykorzystujące formalizm kontrfaktyczny i graficzny, podała Pearl (2000; s. 248). Definicja graficzna wymaga, aby Z spełniał następujące warunki:

gdzie oznacza d -separację, a oznacza wykres, w którym wszystkie strzałki wchodzące w X są odcięte.


Definicja kontrfaktyczna wymaga, aby Z spełnia

gdzie Y x oznacza wartość, którą Y osiągnąłby, gdyby X było x i oznacza niezależność.
Jeśli istnieją dodatkowe współzmienne W, powyższe definicje są modyfikowane tak, że Z kwalifikuje się jako instrument, jeśli dane kryteria są uzależnione od W .
Istotą definicji Pearl jest:
- Równania będące przedmiotem zainteresowania są „strukturalne”, a nie „regresyjne”.
- Termin błędu U oznacza wszystkie czynniki egzogeniczne, które wpływają na Y, gdy X jest utrzymywane na stałym poziomie.
- Instrument Z powinien być niezależny od U.
- Instrument Z nie powinien wpływać na Y, gdy X jest utrzymywane na stałym poziomie (ograniczenie wykluczenia).
- Instrument Z nie powinien być niezależny od X.
Warunki te nie opierają się na określonej postaci funkcjonalnej równań i dlatego mają zastosowanie do równań nieliniowych, w których U może być nieaddytywne (patrz Analiza nieparametryczna). Mają one również zastosowanie do układu wielu równań, w którym X (i inne czynniki) wpływają na Y poprzez kilka zmiennych pośrednich. Zmienna instrumentalna nie musi być przyczyną X ; Pełnomocnictwo takiej przyczyny może być również użyte, jeżeli spełnia warunki 1–5. Ograniczenie wykluczenia (warunek 4) jest zbędne; wynika to z warunków 2 i 3.
Wybór odpowiednich instrumentów
Ponieważ U nie jest obserwowane, wymaganie, aby Z było niezależne od U, nie może być wywnioskowane z danych, a zamiast tego musi być określone na podstawie struktury modelu, tj. procesu generowania danych. Wykresy przyczynowe są reprezentacją tej struktury, a graficzną definicję podaną powyżej można wykorzystać do szybkiego określenia, czy zmienna Z kwalifikuje się jako zmienna instrumentalna przy danym zestawie zmiennych towarzyszących W . Aby zobaczyć, jak, rozważmy następujący przykład.
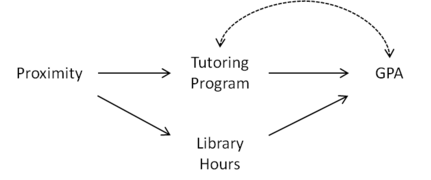
Rysunek 1: Bliskość kwalifikuje się jako zmienna instrumentalna przy danych godzinach bibliotecznych

Rysunek 2: , który służy do określenia, czy Proximity jest zmienną instrumentalną.

Rysunek 3: Bliskość nie kwalifikuje się jako zmienna instrumentalna biorąc pod uwagę Godziny biblioteczne

Rysunek 4: Bliskość kwalifikuje się jako zmienna instrumentalna, o ile nie uwzględnimy godzin pracy biblioteki jako współzmiennej.

_2.png)


Załóżmy, że chcemy oszacować wpływ programu korepetycji uniwersyteckich na średnią ocen ( GPA ). Związek między uczestnictwem w programie korepetycji a GPA może być zakłócany przez wiele czynników. Uczniowie uczestniczący w programie korepetycji mogą bardziej dbać o swoje stopnie lub mieć problemy z pracą. Ta pomyłka jest przedstawiona na rysunkach 1–3 po prawej stronie poprzez dwukierunkowy łuk pomiędzy programem nauczania a GPA. Jeśli studenci są przydzielani do akademików losowo, bliskość akademika do programu korepetycji jest naturalnym kandydatem do bycia zmienną instrumentalną.
Co jednak, jeśli program korepetycji znajduje się w bibliotece uczelni? W takim przypadku Proximity może również spowodować, że uczniowie spędzą więcej czasu w bibliotece, co z kolei poprawi ich GPA (patrz Rysunek 1). Korzystając z wykresu przyczynowego przedstawionego na rysunku 2, widzimy, że Proximity nie kwalifikuje się jako zmienna instrumentalna, ponieważ jest połączona z GPA przez ścieżkę Godziny biblioteki zbliżeniowej GPA w . Jeśli jednak kontrolujemy godziny pracy biblioteki, dodając je jako współzmienną, to Proximity staje się zmienną instrumentalną, ponieważ Proximity jest oddzielone od GPA dla danej godziny pracy biblioteki w .

Załóżmy teraz, że zauważamy, że „naturalna zdolność” ucznia wpływa na liczbę godzin spędzonych w bibliotece, a także na jego GPA, jak na rysunku 3. Korzystając z wykresu przyczynowego, widzimy, że godziny pracy w bibliotece są zderzaczem i uwarunkowanie na nim otwiera ścieżkę Godzin Biblioteki Zbliżeniowej GPA. W rezultacie Proximity nie może być wykorzystana jako zmienna instrumentalna.

Na koniec załóżmy, że godziny pracy biblioteki nie wpływają w rzeczywistości na GPA, ponieważ studenci, którzy nie uczą się w bibliotece, po prostu uczą się gdzie indziej, jak na rysunku 4. W tym przypadku kontrolowanie godzin biblioteki nadal otwiera fałszywą ścieżkę z sąsiedztwa do GPA. Jeśli jednak nie kontrolujemy godzin biblioteki i usuniemy je jako współzmienną, to Proximity może być ponownie użyte jako zmienna instrumentalna.
Oszacowanie
Teraz wracamy i bardziej szczegółowo omawiamy mechanikę IV. Załóżmy, że dane są generowane przez proces formularza

gdzie
- I indeksuje obserwacje,
- jest i -tą wartością zmiennej zależnej,
- jest wektorem i- tej wartości zmiennej(-ych) niezależnej(ych) i stałą,
- jest i -tą wartością nieobserwowanego składnika błędu reprezentującego wszystkie przyczyny inne niż , oraz
- jest nieobserwowanym wektorem parametrów.



Wektor parametrów jest efektem przyczynowym zmiany o jedną jednostkę w każdym elemencie , przy czym wszystkie inne przyczyny są stałe. Celem ekonometrycznym jest oszacowanie . Dla uproszczenia załóżmy, że remisy e są nieskorelowane i są wyciągane z rozkładów o tej samej wariancji (to znaczy, że błędy są szeregowo nieskorelowane i homoskedastyczne ).
Załóżmy również, że zaproponowano model regresji o nominalnie tej samej postaci. Biorąc pod uwagę losową próbkę obserwacji T z tego procesu, zwykłym estymatorem najmniejszych kwadratów jest

gdzie X , y i e oznaczają wektory kolumnowe o długości T . Równanie to jest podobne do równania zawartego we wstępie (jest to macierzowa wersja tego równania). Gdy X i e są nieskorelowane , w pewnych warunkach regularności drugi składnik ma wartość oczekiwaną zależną od X równego zero i zbiega się do zera w limicie, więc estymator jest nieobciążony i spójny. Kiedy X i inne niezmierzone zmienne przyczynowe zwinięte w składnik e są skorelowane, jednak estymator MNK jest na ogół stronniczy i niespójny dla β . W tym przypadku prawidłowe jest wykorzystanie oszacowań do przewidywania wartości y przy danych wartościach X , ale oszacowanie nie przywraca wpływu przyczynowego X na y .

Aby odzyskać bazowy parametr , wprowadzamy zestaw zmiennych Z, który jest silnie skorelowany z każdym endogennym składnikiem X, ale (w naszym podstawowym modelu) nie jest skorelowany z e . Dla uproszczenia można uznać X za macierz T × 2 złożoną z kolumny stałych i jednej zmiennej endogenicznej, a Z za T × 2 składającą się z kolumny stałych i jednej zmiennej instrumentalnej. Jednak technika ta uogólnia, że X jest macierzą stałej i, powiedzmy, 5 zmiennych endogenicznych, przy czym Z jest macierzą złożoną ze stałej i 5 instrumentów. W poniższej dyskusji założymy, że X jest macierzą T × K i pozostawimy tę wartość K nieokreśloną. Estymator, w którym X i Z są macierzami T × K , jest określany jako właśnie zidentyfikowany .
Załóżmy, że zależność między każdym składnikiem endogennym x i a instrumentami jest dana wzorem

Najpopularniejsza specyfikacja IV wykorzystuje następujący estymator:

Ta specyfikacja zbliża się do prawdziwego parametru, gdy próbka staje się duża, o ile w prawdziwym modelu:


Dopóki w podstawowym procesie, który generuje dane, odpowiednie użycie estymatora IV zidentyfikuje ten parametr. Działa to, ponieważ IV rozwiązuje unikalny parametr, który spełnia , i dlatego skupia się na prawdziwym podstawowym parametrze wraz ze wzrostem wielkości próby.
Teraz rozszerzenie: załóżmy, że w równaniu będącym przedmiotem zainteresowania jest więcej instrumentów niż współzmiennych, więc Z jest macierzą T × M z M > K . Nazywa się to często przypadkiem nadmiernie zidentyfikowanym . W takim przypadku można zastosować uogólnioną metodę momentów (GMM). Estymator GMM IV to

gdzie odnosi się do macierzy projekcji .


To wyrażenie zwija się do pierwszego, gdy liczba instrumentów jest równa liczbie zmiennych towarzyszących w interesującym równaniu. Nadmiernie zidentyfikowane IV jest zatem uogólnieniem właśnie zidentyfikowanego IV.
Opracowanie wyrażenia:


W przypadku właśnie zidentyfikowanym mamy tyle instrumentów, ile jest współzmiennych, tak że wymiar X jest taki sam jak wymiar Z . Stąd i wszystkie są macierzami kwadratowymi o tym samym wymiarze. Możemy rozwinąć odwrotność, korzystając z faktu, że dla dowolnej odwracalnej macierzy n -by- n A i B , ( AB ) −1 = B −1 A −1 (patrz Invertible matrix#Properties ):



Odniesienie: patrz Davidson i Mackinnnon (1993)
Istnieje równoważny niedostatecznie zidentyfikowany estymator dla przypadku, w którym m < k . Ponieważ parametry są rozwiązaniami zbioru równań liniowych, niedostatecznie zidentyfikowany model wykorzystujący zbiór równań nie ma unikalnego rozwiązania.

Interpretacja jako dwustopniowa najmniejszych kwadratów
Jedną z metod obliczeniowych, którą można wykorzystać do obliczenia szacunków IV, jest dwustopniowa metoda najmniejszych kwadratów (2SLS lub TSLS). W pierwszym etapie każda zmienna objaśniająca, która jest endogeniczną współzmienną w równaniu zainteresowania, jest regresowana względem wszystkich egzogenicznych zmiennych w modelu, w tym zarówno egzogenicznych współzmiennych w równaniu zainteresowania, jak i wyłączonych instrumentów. Przewidywane wartości z tych regresji uzyskuje się:
Etap 1: Cofnij każdą kolumnę X do Z , ( ):


i zapisz przewidywane wartości:

W drugim etapie regresja zainteresowania jest szacowana jak zwykle, z tym wyjątkiem, że na tym etapie każda współzmienna endogenna jest zastępowana przewidywanymi wartościami z pierwszego etapu:
Etap 2: Regresja Y względem przewidywanych wartości z pierwszego etapu:

co daje

Ta metoda jest ważna tylko w modelach liniowych. W przypadku kategorycznych endogenicznych współzmiennych można pokusić się o zastosowanie innego pierwszego etapu niż zwykłe najmniejszych kwadratów, takiego jak model Probita dla pierwszego etapu, a następnie OLS dla drugiego. Jest to powszechnie znane w literaturze ekonometrycznej jako zakazana regresja , ponieważ oszacowania parametrów II stopnia IV są zgodne tylko w szczególnych przypadkach.
Typowy estymator OLS to: . Zastąpienie i odnotowanie, że jest to macierz symetryczna i idempotentna , aby




Wynikowy estymator jest liczbowo identyczny z wyrażeniem wyświetlonym powyżej. Aby poprawnie obliczyć macierz kowariancji, należy wprowadzić niewielką poprawkę do sumy kwadratów reszt w dopasowanym modelu drugiego etapu .
Analiza nieparametryczna
Gdy postać równań strukturalnych jest nieznana, zmienną instrumentalną można jeszcze zdefiniować za pomocą równań:



gdzie i są dwiema dowolnymi funkcjami i są niezależne od . Jednak w przeciwieństwie do modeli liniowych pomiary i nie pozwalają na identyfikację średniego wpływu przyczynowego na , oznaczanego ACE




![{\text{ACE}}=\Pr(y\mid {\text{do}}(x))=\nazwa operatora {E}_{u}[f(x,u)].](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6ea36b8f79d0df3bb0e66e1b9273b9c9ae67edb)
Balke i Pearl [1997] wyprowadzili ścisłe ograniczenia z ACE i wykazali, że mogą one dostarczyć cennych informacji na temat znaku i rozmiaru ACE.
W analizie liniowej nie ma testu falsyfikującego założenie, że jest instrumentalne w stosunku do pary . To nie jest przypadek, gdy jest dyskretny. Pearl (2000) wykazał, że dla wszystkich i , następujące ograniczenie, zwane „Nierównościami Instrumentalnymi” musi być spełnione, gdy tylko spełnia dwa powyższe równania:

![\max _{x}\sum _{y}[\max _{z}\Pr(y,x\mid z)]\leq 1.](https://wikimedia.org/api/rest_v1/media/math/render/svg/b089badc50cd6306cc6c673f45027813e1ebc23e)
Interpretacja w warunkach leczenia niejednorodność
Powyższe wyjaśnienie zakłada, że efekt przyczynowy zainteresowania nie zmienia się w różnych obserwacjach, to znaczy jest stały. Ogólnie rzecz biorąc, różni badani będą w różny sposób reagować na zmiany w „leczeniu” x . Gdy ta możliwość zostanie rozpoznana, średni efekt w populacji zmiany x na y może różnić się od efektu w danej subpopulacji. Na przykład średni efekt programu szkolenia zawodowego może znacznie różnić się w zależności od grupy osób, które faktycznie biorą udział w szkoleniu, i grupy, która nie zdecyduje się na szkolenie. Z tych powodów metody IV odwołują się do ukrytych założeń dotyczących reakcji behawioralnej lub, bardziej ogólnie, założeń dotyczących korelacji między reakcją na leczenie a skłonnością do leczenia.
Standardowy estymator IV może odzyskać lokalne średnie efekty leczenia (LATE) zamiast średnich efektów leczenia (ATE). Imbens i Angrist (1994) wykazują, że liniowe oszacowanie IV może być interpretowane w słabych warunkach jako średnia ważona średnich lokalnych efektów leczenia, gdzie wagi zależą od elastyczności endogennego regresora na zmiany zmiennych instrumentalnych. Z grubsza oznacza to, że wpływ zmiennej jest ujawniany tylko dla subpopulacji, na które mają wpływ obserwowane zmiany instrumentów, oraz że subpopulacje, które najbardziej reagują na zmiany instrumentów, będą miały największy wpływ na wielkość oszacowania IV.
Na przykład, jeśli naukowiec w regresji zarobków wykorzystuje obecność uczelni z dotacją gruntową jako narzędzia kształcenia w college'u, identyfikuje wpływ college'u na zarobki w subpopulacji, która uzyskałaby dyplom ukończenia college'u, gdyby uczelnia była obecna, ale która nie uzyskać dyplomu, jeśli nie ma kolegium. To empiryczne podejście, bez dalszych założeń, nie mówi badaczowi nic o wpływie college'u na ludzi, którzy albo zawsze, albo nigdy nie uzyskaliby dyplomu, niezależnie od tego, czy istnieje lokalna uczelnia.
Problem ze słabymi instrumentami
Jak zauważają Bound, Jaeger i Baker (1995), problemem jest wybór „słabych” instrumentów, instrumentów, które są słabymi predyktorami predyktora pytań endogenicznych w równaniu pierwszego etapu. W takim przypadku przewidywanie predyktora pytania przez instrument będzie słabe, a przewidywane wartości będą miały bardzo małą zmienność. W związku z tym jest mało prawdopodobne, aby odniosły one duży sukces w przewidywaniu ostatecznego wyniku, gdy zostaną użyte do zastąpienia predyktora pytania w równaniu drugiego etapu.
W kontekście omówionego powyżej przykładu palenia i zdrowia, podatki od wyrobów tytoniowych są słabym instrumentem palenia, jeśli palenie w dużej mierze nie reaguje na zmiany w podatkach. Jeśli wyższe podatki nie skłaniają ludzi do rzucenia palenia (lub nie rozpoczęcia palenia), to różnice w stawkach podatkowych nie mówią nam nic o wpływie palenia na zdrowie. Jeżeli podatki wpływają na zdrowie w inny sposób niż przez ich wpływ na palenie, wówczas instrumenty są nieważne, a podejście oparte na zmiennych instrumentalnych może dawać mylące wyniki. Na przykład miejsca i czasy, w których populacje są stosunkowo świadome zdrowotnie, mogą zarówno wprowadzać wysokie podatki od tytoniu, jak i wykazywać lepszy stan zdrowia, nawet przy stałych wskaźnikach palenia, więc zaobserwowalibyśmy korelację między podatkami zdrowotnymi a podatkami od tytoniu, nawet gdyby palenie nie miało żadnego wpływu na zdrowie. W tym przypadku mylilibyśmy się, wywnioskując przyczynowy wpływ palenia na zdrowie na podstawie zaobserwowanej korelacji między podatkami od wyrobów tytoniowych a stanem zdrowia.
Testowanie słabych instrumentów
Siłę instrumentów można ocenić bezpośrednio, ponieważ zarówno endogenne współzmienne, jak i instrumenty są obserwowalne. Powszechną praktyczną zasadą dla modeli z jednym regresorem endogenicznym jest: statystyka F w stosunku do wartości zerowej, zgodnie z którą wyłączone instrumenty są nieistotne w pierwszym etapie regresji, powinna być większa niż 10.
Wnioskowanie statystyczne i testowanie hipotez
Gdy współzmienne są egzogeniczne, właściwości estymatora MNK dla małej próby można wyprowadzić w prosty sposób, obliczając momenty estymatora zależne od X . Gdy niektóre współzmienne są endogeniczne, tak że zaimplementowano estymację zmiennych instrumentalnych, nie można w ten sposób uzyskać prostych wyrażeń dla momentów estymatora. Ogólnie rzecz biorąc, estymatory zmiennych instrumentalnych mają tylko pożądane właściwości asymptotyczne, a nie skończoną próbkę, a wnioskowanie opiera się na asymptotycznych przybliżeniach rozkładu próbkowania estymatora. Nawet gdy instrumenty nie są skorelowane z błędem w równaniu będącym przedmiotem zainteresowania i gdy instrumenty nie są słabe, właściwości estymatora zmiennych instrumentalnych na próbie skończonej mogą być słabe. Na przykład dokładnie zidentyfikowane modele generują estymatory skończonej próby bez momentów, więc można powiedzieć, że estymator nie jest ani obciążony, ani nieobciążony, nominalny rozmiar statystyk testowych może być znacznie zniekształcony, a szacunki mogą być często dalekie od prawdziwej wartości parametru.
Testowanie ograniczenia wykluczenia
Założenie, że instrumenty nie są skorelowane ze składnikiem błędu w równaniu będącym przedmiotem zainteresowania, nie jest testowalne w dokładnie zidentyfikowanych modelach. Jeśli model jest nadmiernie zidentyfikowany, dostępne są informacje, które można wykorzystać do przetestowania tego założenia. Najczęstszy test tych nadmiernie identyfikujących ograniczeń , zwany testem Sargana-Hansena , opiera się na obserwacji, że reszty powinny być nieskorelowane ze zbiorem zmiennych egzogenicznych, jeśli instrumenty są naprawdę egzogeniczne. Statystykę testu Sargana-Hansena można obliczyć jako (liczbę obserwacji pomnożoną przez współczynnik determinacji ) z regresji MNK reszt na zbiór zmiennych egzogenicznych. Ta statystyka będzie asymptotycznie chi-kwadrat z m − k stopni swobody pod zerem, że składnik błędu nie jest skorelowany z instrumentami.

Zastosowanie do modeli z efektami losowymi i stałymi
W standardowych modelach efektów losowych (RE) i efektów stałych (FE) dla danych panelowych zakłada się, że zmienne niezależne są nieskorelowane ze składnikami błędu. Pod warunkiem dostępności odpowiednich instrumentów, metody RE i FE obejmują przypadek, w którym niektóre zmienne objaśniające mogą być endogeniczne. Podobnie jak w otoczeniu egzogenicznym, model RE ze zmiennymi instrumentalnymi (REIV) wymaga bardziej rygorystycznych założeń niż model FE ze zmiennymi instrumentalnymi (FEIV), ale wydaje się być bardziej wydajny w odpowiednich warunkach.
Aby naprawić pomysły, rozważ następujący model:

gdzie jest niezauważalna dla danego urządzenia Efekt przedłużonego niezmienna (połączenie to efekt nie zauważony) i może być skorelowana z o s ewentualnie różnią się od t . Załóżmy, że istnieje zestaw ważnych instrumentów .




W ustawieniu REIV, kluczowe założenia obejmują to, że jest nieskorelowane, a także dla . W rzeczywistości, aby estymator REIV był skuteczny, konieczne są warunki silniejsze niż brak korelacji między instrumentami i nieobserwowany efekt.



Z drugiej strony estymator FEIV wymaga jedynie, aby instrumenty były egzogeniczne z błędami po uwarunkowaniu nieobserwowanym efektem, tj . . Warunek FEIV pozwala na dowolną korelację między instrumentami i nieobserwowanym efektem. Jednak ta ogólność nie jest darmowa: nie są dozwolone zmienne objaśniające i instrumentalne niezmienne w czasie. Podobnie jak w zwykłej metodzie FE, estymator używa zmiennych zaburzonych w czasie, aby usunąć nieobserwowany efekt. Dlatego estymator FEIV miałby ograniczone zastosowanie, gdyby interesujące zmienne obejmowały zmienne w czasie.
![{\ Displaystyle E [u_ {it} \ mid z_ {i}, c_ {i}] = 0 [1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b666ac512b37eb9b633068404cb5c21dba18ef14)
Powyższa dyskusja przebiega równolegle z egzogenicznym przypadkiem modeli RE i FE. W przypadku egzogenicznym RE zakłada brak korelacji między zmiennymi objaśniającymi a efektem nieobserwowanym, a FE pozwala na arbitralną korelację między nimi. Podobnie jak w przypadku standardowym, REIV wydaje się być bardziej wydajny niż FEIV, pod warunkiem, że zostaną spełnione odpowiednie założenia.
Zobacz też
- Binarny model odpowiedzi z ciągłymi endogennymi zmiennymi objaśniającymi
- Funkcja kontrolna (ekonometria)
- Optymalne instrumenty
Bibliografia
Dalsza lektura
- Greene, William H. (2008). Analiza ekonometryczna (wyd. szóste). Upper Saddle River: Pearson Prentice-Hall. str. 314 -353. Numer ISBN 978-0-13-600383-0.
- Gujarati, Damodar N .; Porter, Świt C. (2009). Ekonometria podstawowa (wyd. piąte). Nowy Jork: McGraw-Hill Irwin. s. 711 -736. Numer ISBN 978-0-07-337577-9.
- Sargan, Denis (1988). Wykłady z zaawansowanej teorii ekonometrycznej . Oksford: Basil Blackwell. s. 42–67. Numer ISBN 978-0-631-14956-9.
- Wooldridge, Jeffrey M. (2013). Ekonometria wprowadzająca: nowoczesne podejście (piąta edycja międzynarodowa). Mason, OH: Południowo-Zachodni. s. 490-528. Numer ISBN 978-1-111-53439-4.
Bibliografia
- Wooldridge, J. (1997): Quasi-Likelihood Methods for Count Data, Handbook of Applied Econometrics, tom 2, wyd. MH Pesaran i P. Schmidt, Oxford, Blackwell, s. 352-406
- Terza, JV (1998): „Szacowanie modeli zliczania z endogennym przełączaniem: wybór próbki i endogenne efekty leczenia”. Journal of Econometrics (84), s. 129–154
- Wooldridge, J. (2002): "Analiza ekonometryczna przekroju poprzecznego i danych panelowych", MIT Press , Cambridge, Massachusetts.
Zewnętrzne linki
- Rozdział z podręcznika Daniela McFaddena
- Wykład z ekonometrii (temat: zmienna instrumentalna) na YouTube autorstwa Marka Thomy .
- Wykład z ekonometrii (temat: dwuetapowy najmniejszy kwadrat) na YouTube autorstwa Marka Thoma