
Zejście gradientowe - Gradient descent
Gradient zejście jest pierwszego rzędu iteracyjny optymalizacji algorytm dla znalezienia lokalnego minimum o różniczkowalnej funkcji . Chodzi o to, aby powtarzać kroki w kierunku przeciwnym do gradientu (lub przybliżonego gradientu) funkcji w bieżącym punkcie, ponieważ jest to kierunek najbardziej stromego opadania. I odwrotnie, krok w kierunku gradientu prowadzi do lokalnego maksimum tej funkcji; procedura ta nazywana jest wówczas wznoszeniem gradientowym .
Gradient zejście jest powszechnie przypisywane Cauchy'ego , który pierwszy zaproponował go w 1847 roku Hadamard niezależnie zaproponował podobną metodę w 1907. Jego właściwości konwergencji dla nieliniowych problemów optymalizacyjnych zostały po raz pierwszy badany przez Haskell Curry w 1944 roku, przy czym metoda coraz dobrze badane i używany w następnych dziesięcioleciach, często nazywany również najbardziej stromym zejściem.
Opis

Gradient zejście opiera się na obserwacji, że jeśli funkcja multi-zmienna jest określona i różniczkowalna w pewnym otoczeniu punktu , a następnie maleje najszybciej jeśli ktoś idzie od w kierunku gradientu negatyw w . Wynika z tego, że jeśli





na wystarczająco małe, to . Innymi słowy, termin jest odejmowany, ponieważ chcemy poruszać się pod kątem, w kierunku minimum lokalnego. Mając na uwadze tę obserwację, zaczynamy od odgadnięcia lokalnego minimum i rozważamy ciąg taki, że






Mamy ciąg monotoniczny

więc miejmy nadzieję, że sekwencja zbiega się do pożądanego minimum lokalnego. Zauważ, że wartość rozmiaru kroku może się zmieniać w każdej iteracji. Przy pewnych założeniach dotyczących funkcji (na przykład wypukła i Lipschitz ) i szczególnych wyborach (np. wybranych przez wyszukiwanie liniowe spełniające warunki Wolfe'a lub metodę Barzilai-Borweina pokazaną poniżej),



![{\ Displaystyle \ gamma _ {n} = {\ Frac {\ po lewej | \ po lewej (\ mathbf {x} _ {n} - \ mathbf {x} _ {n-1} \ po prawej) ^ {T} \ po lewej [\nabla F(\mathbf {x} _{n})-\nabla F(\mathbf {x} _{n-1})\right]\right|}{\left\|\nabla F(\mathbf {x} _{n})-\nabla F(\mathbf {x} _{n-1})\right\|^{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4bd0be3d2e50d47f18b4aeae8643e00ff7dd2e9)
można zagwarantować konwergencję do lokalnego minimum. Gdy funkcja jest wypukła , wszystkie minima lokalne są również minimami globalnymi, więc w tym przypadku gradient może być zbieżny do rozwiązania globalnego.
Proces ten jest zilustrowany na sąsiednim rysunku. Tutaj zakłada się, że jest zdefiniowana na płaszczyźnie, a jej wykres ma kształt misy . Niebieskie krzywe to linie konturowe , czyli regiony, na których wartość jest stała. Czerwona strzałka wychodząca z punktu pokazuje kierunek ujemnego gradientu w tym punkcie. Zauważ, że (ujemny) gradient w punkcie jest prostopadły do linii konturu przechodzącej przez ten punkt. Widzimy, że zejście gradientowe prowadzi nas do dna miski, czyli do punktu, w którym wartość funkcji jest minimalna.
Analogia do zrozumienia opadania gradientu
.jpg)
Podstawową intuicję stojącą za spadkiem gradientowym można zilustrować za pomocą hipotetycznego scenariusza. Człowiek utknął w górach i próbuje zejść (tj. próbuje znaleźć globalne minimum). Jest gęsta mgła, tak że widoczność jest bardzo niska. Dlatego ścieżka w dół góry nie jest widoczna, więc muszą korzystać z lokalnych informacji, aby znaleźć minimum. Mogą stosować metodę schodzenia gradientowego, która polega na przyjrzeniu się stromości wzgórza w ich aktualnej pozycji, a następnie podążaniu w kierunku najbardziej stromego zejścia (tj. w dół). Gdyby próbowali znaleźć szczyt góry (tj. maksimum), wówczas podążaliby w kierunku najbardziej stromego podejścia (tj. pod górę). Korzystając z tej metody, w końcu znaleźliby drogę w dół góry lub prawdopodobnie utknęli w jakiejś dziurze (tj. lokalnym minimum lub punkcie siodła ), jak górskie jezioro. Załóżmy jednak również, że stromość wzgórza nie jest od razu oczywista przy prostej obserwacji, ale raczej wymaga wyrafinowanego narzędzia do pomiaru, które osoba akurat posiada. Pomiar stromości wzgórza za pomocą instrumentu zajmuje trochę czasu, dlatego powinni zminimalizować jego użycie, jeśli chcą zejść z góry przed zachodem słońca. Trudność polega zatem na wyborze częstotliwości, z jaką należy mierzyć stromość wzgórza, aby nie zboczyć z trasy.
W tej analogii osoba reprezentuje algorytm, a ścieżka schodząca z góry reprezentuje sekwencję ustawień parametrów, które algorytm zbada. Stromość wzgórza reprezentuje nachylenie powierzchni błędu w tym punkcie. Instrumentem używanym do pomiaru stromości jest różniczkowanie (nachylenie powierzchni błędu można obliczyć, biorąc pochodną kwadratu funkcji błędu w tym punkcie). Kierunek, w którym wybierają podróż, jest zgodny z nachyleniem powierzchni błędu w tym punkcie. Czas, przez jaki podróżują przed wykonaniem kolejnego pomiaru, to rozmiar kroku.
Przykłady
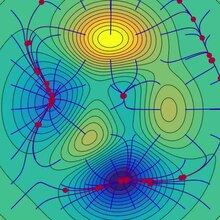
Zejście gradientowe ma problemy z funkcjami patologicznymi, takimi jak pokazana tutaj funkcja Rosenbrocka .

Funkcja Rosenbrocka ma wąską zakrzywioną dolinę, która zawiera minimum. Dno doliny jest bardzo płaskie. Ze względu na zakrzywioną płaską dolinę optymalizacja przebiega powoli zygzakiem z małymi krokami w kierunku minimum. Whiplash Gradient Descent rozwiązuje ten problem w szczególności.

Zygzakowaty charakter tej metody jest również widoczny poniżej, gdzie stosuje się metodę opadania gradientu

.png)
.png)
Wybór wielkości kroku i kierunku opadania
Ponieważ użycie zbyt małego kroku spowolniłoby zbieżność, a zbyt dużego doprowadziłoby do rozbieżności, znalezienie dobrego ustawienia jest ważnym problemem praktycznym. Philip Wolfe opowiadał się również za stosowaniem „sprytnych wyborów kierunku [zejścia]” w praktyce. Chociaż użycie kierunku, który odbiega od najbardziej stromego kierunku opadania, może wydawać się sprzeczne z intuicją, chodzi o to, że mniejsze nachylenie można zrekompensować, utrzymując się na znacznie większej odległości.
Aby zrozumieć to matematycznie, użyjmy kierunku i rozmiaru kroku i rozważmy bardziej ogólną aktualizację:


- .

Znalezienie dobrych ustawień i wymaga trochę przemyślenia. Przede wszystkim chcielibyśmy, aby kierunek aktualizacji wskazywał w dół. Matematycznie, pozwalając na oznaczenie kąta pomiędzy i , wymaga to, aby powiedzieć więcej, potrzebujemy więcej informacji o funkcji celu, którą optymalizujemy. Przy dość słabym założeniu, które jest ciągle różniczkowalne, możemy udowodnić, że:



-
( 1 )
![{\ Displaystyle F (\ mathbf {a} _ {n + 1}) \ leq F (\ mathbf {a} _ {n}) - \ gamma _ {n} \ | \ nabla F (\ mathbf {a} _ {n})\|_{2}\|\mathbf {p} _{n}\|_{2}\left[\cos \theta _{n}-\max _{t\in [0,1 ]}{\frac {\|\nabla F(\mathbf {a} _{n}-t\gamma _{n}\mathbf {p} _{n})-\nabla F(\mathbf {a} _ {n})\|_{2}}{\|\nabla F(\mathbf {a} _{n})\|_{2}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1433794e842e36580db8fa219ae5ca650010d6d6)
Ta nierówność implikuje, że kwota, o którą możemy być pewni, że funkcja zostanie zmniejszona, zależy od kompromisu między dwoma wyrazami w nawiasach kwadratowych. Pierwszy wyraz w nawiasach kwadratowych mierzy kąt między kierunkiem opadania a gradientem ujemnym. Drugi termin mierzy, jak szybko gradient zmienia się wzdłuż kierunku opadania.
W zasadzie nierówność ( 1 ) można zoptymalizować i wybrać optymalny rozmiar kroku i kierunek. Problem polega na tym, że ocena drugiego składnika w nawiasach kwadratowych wymaga oceny , a dodatkowe oceny gradientu są generalnie drogie i niepożądane. Oto kilka sposobów na obejście tego problemu:

- Zrezygnuj z zalet sprytnego kierunku opadania, ustawiając , i użyj wyszukiwania linii, aby znaleźć odpowiedni rozmiar kroku , taki, który spełnia warunki Wolfe'a .
- Zakładając, że jest to podwójnie różniczkowe, użyj jego hessu do oszacowania Następnie wybierz i optymalizując nierówność ( 1 ).
- Zakładając, że jest to Lipschitz , użyj jego stałej Lipschitza do ograniczenia Następnie wybierz i optymalizując nierówność ( 1 ).
- Utwórz niestandardowy model for . Następnie wybierz i optymalizując nierówności ( 1 ).
- Przy silniejszych założeniach dotyczących funkcji, takich jak wypukłość , możliwe są bardziej zaawansowane techniki .





![{\ Displaystyle \ max _ {t \ w [0,1]} {\ Frac {\ | \ nabla F (\ mathbf {a} _ {n}-t \ gamma _ {n} \ mathbf {p} _ { n})-\nabla F(\mathbf {a} _{n})\|_{2}}{\|\nabla F(\mathbf {a} _{n})\|_{2}}} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/982e8508a3147c2ba4e45b7f88fdda4727d13699)
Zazwyczaj postępując zgodnie z jednym z powyższych przepisów, można zagwarantować zbieżność z lokalnym minimum. Gdy funkcja jest wypukła , wszystkie minima lokalne są również minimami globalnymi, więc w tym przypadku gradient może być zbieżny do rozwiązania globalnego.
Rozwiązanie układu liniowego

Opadanie gradientowe może być wykorzystane do rozwiązania układu równań liniowych

przeformułowany jako kwadratowy problem minimalizacji. Jeżeli macierz systemu jest rzeczywista symetryczna i dodatnio określona , funkcję celu definiuje się jako funkcję kwadratową, z minimalizacją


aby

Dla ogólnej macierzy rzeczywistej , liniowe najmniejszych kwadratów definiują

W tradycyjnych liniowych najmniejszych kwadratów dla prawdziwych i na euklidesowej normą jest używany, w którym to przypadku


Wyszukiwania linia minimalizacja znalezienie lokalnie optymalny rozmiar krok na każdej iteracji może być wykonane analitycznie dla funkcji kwadratowej i jawnych wzorów na lokalnie Optymalna są znane.
Na przykład dla rzeczywistej macierzy symetrycznej i dodatnio określonej prosty algorytm może wyglądać następująco:

Aby uniknąć podwójnego mnożenia na iterację, zauważamy, że implikuje , co daje tradycyjnemu algorytmowi,



Metoda ta jest rzadko wykorzystywana do rozwiązywania równań liniowych, a metoda gradientu sprzężonego jest jedną z najpopularniejszych alternatyw. Liczba gradientów iteracji opadania jest zwykle proporcjonalna do widmowej liczby stan matrycy systemu (stosunek maksymalnej do minimalnej wartości własnych w ) , przy czym zbieżność koniugatu metodą gradientu jest typowo określane przez pierwiastek kwadratowy liczby stanów chorobowych, np , jest znacznie szybszy. Obie metody mogą skorzystać na uwarunkowaniu wstępnym , gdzie opadanie gradientowe może wymagać mniej założeń dotyczących uwarunkowania wstępnego.


Rozwiązanie systemu nieliniowego
Opadanie gradientowe można również wykorzystać do rozwiązania układu równań nieliniowych . Poniżej znajduje się przykład, który pokazuje, jak użyć gradientu do rozwiązania dla trzech nieznanych zmiennych, x 1 , x 2 i x 3 . Ten przykład pokazuje jedną iterację opadania gradientu.
Rozważ nieliniowy układ równań

Przedstawmy powiązaną funkcję

gdzie

Można by teraz zdefiniować funkcję celu
![{\ Displaystyle F (\ mathbf {x} ) = {\ Frac {1} {2}} G ^ {\ operatorname {T}} (\ mathbf {x}) G (\ mathbf {x}) = {\ Frac {1}{2}}\left[\left(3x_{1}-\cos(x_{2}x_{3})-{\frac {3}{2}}\right)^{2}+\ left(4x_{1}^{2}-625x_{2}^{2}+2x_{2}-1\right)^{2}+\left(\exp(-x_{1}x_{2}) +20x_{3}+{\frac {10\pi -3}{3}}\w prawo)^{2}\w prawo],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31ebfa155b6d0cdef7771ecacf28d5179dd9b111)
które postaramy się zminimalizować. Jako wstępne przypuszczenie użyjmy

Wiemy to

gdzie macierz Jakobian jest dana przez


Obliczamy:

Zatem

oraz




Teraz trzeba znaleźć odpowiedni taki, aby


Można to zrobić za pomocą dowolnego z różnych algorytmów wyszukiwania wierszy . Można też po prostu zgadywać, co daje


Oceniając funkcję celu przy tej wartości, daje

Spadek od do wartości następnego kroku


to znaczny spadek funkcji celu. Dalsze kroki jeszcze bardziej obniżyłyby jego wartość, aż do znalezienia przybliżonego rozwiązania systemu.
Uwagi
Zejście gradientowe działa w przestrzeniach o dowolnej liczbie wymiarów, nawet nieskończenie wymiarowych. W tym drugim przypadku przestrzeń poszukiwań jest zwykle przestrzenią funkcji i oblicza się pochodną Frécheta funkcjonału, który ma zostać zminimalizowany, aby określić kierunek opadania.
To gradientowe opadanie działa w dowolnej liczbie wymiarów (przynajmniej skończonej liczbie) może być postrzegane jako konsekwencja nierówności Cauchy'ego-Schwarza . Artykuł ten dowodzi, że wielkość iloczynu skalarnego (kropkowego) dwóch wektorów dowolnego wymiaru jest maksymalizowana, gdy są one współliniowe. W przypadku opadania gradientu miałoby to miejsce wtedy, gdy wektor korekt zmiennych niezależnych jest proporcjonalny do wektora gradientu pochodnych cząstkowych.
Opadanie gradientu może zająć wiele iteracji, aby obliczyć lokalne minimum z wymaganą dokładnością , jeśli krzywizna w różnych kierunkach jest bardzo różna dla danej funkcji. W przypadku takich funkcji uwarunkowanie wstępne , które zmienia geometrię przestrzeni w celu ukształtowania zestawów poziomów funkcji, takich jak koncentryczne okręgi , leczy powolną zbieżność. Konstruowanie i stosowanie uwarunkowań wstępnych może być jednak kosztowne obliczeniowo.
Opadanie gradientowe można połączyć z wyszukiwaniem linii , znajdując lokalnie optymalny rozmiar kroku w każdej iteracji. Wykonywanie wyszukiwania linii może być czasochłonne. I odwrotnie, użycie ustalonego małego może dać słabą zbieżność.
Metody oparte na metodzie Newtona i odwróceniu hessu przy użyciu sprzężonych technik gradientowych mogą być lepszymi alternatywami. Ogólnie rzecz biorąc, takie metody zbiegają się w mniejszej liczbie iteracji, ale koszt każdej iteracji jest wyższy. Przykładem jest metoda BFGS polegająca na obliczeniu na każdym kroku macierzy, przez którą mnożony jest wektor gradientu, aby przejść w „lepszym” kierunku, połączona z bardziej wyrafinowanym algorytmem wyszukiwania linii , aby znaleźć „najlepszą” wartość For skrajnie duże problemy, w których dominują kwestie pamięci komputerowej, należy zastosować metodę ograniczonej pamięci, taką jak L-BFGS, zamiast BFGS lub najbardziej strome zejście.

Zejście gradientowe można postrzegać jako zastosowanie metody Eulera do rozwiązywania równań różniczkowych zwyczajnych do przepływu gradientowego . Z kolei to równanie może być wyprowadzone jako optymalny regulator dla układu sterowania o podanym w sprzężeniu zwrotnym .




Modyfikacje
Opadanie gradientowe może zbiegać się do lokalnego minimum i zwalniać w sąsiedztwie punktu siodełkowego . Nawet w przypadku nieograniczonej minimalizacji kwadratowej opadanie gradientu rozwija zygzakowaty wzór kolejnych iteracji w miarę postępu iteracji, co powoduje powolną zbieżność. Zaproponowano wiele modyfikacji gradientu opadania w celu usunięcia tych braków.
Szybkie metody gradientowe
Jurij Niestierow zaproponował prostą modyfikację, która umożliwia szybszą zbieżność problemów wypukłych i od tego czasu jest dalej uogólniana. W przypadku problemów gładkich bez ograniczeń metoda ta nazywana jest metodą szybkiego gradientu (FGM) lub metodą gradientu przyspieszonego (AGM). W szczególności, jeśli funkcja różniczkowalna jest wypukła i jest funkcją Lipschitza i nie zakłada się, że jest silnie wypukła , wówczas błąd wartości celu generowanego na każdym kroku metodą gradientu opadania będzie ograniczony przez . Używając techniki przyspieszenia Niestierowa, błąd zmniejsza się przy . Wiadomo, że tempo spadku funkcji kosztu jest optymalne dla metod optymalizacji pierwszego rzędu. Niemniej jednak istnieje możliwość ulepszenia algorytmu poprzez zmniejszenie współczynnika stałego. Zoptymalizowane metody gradientowe (OGM) redukuje się, że stała się o współczynnik dwa, a to metoda optymalna pierwszego rzędu problemów na dużą skalę.




W przypadku problemów z ograniczeniami lub nierównych, FGM Niestierowa nazywana jest metodą szybkiego gradientu proksymalnego (FPGM), czyli przyspieszeniem metody gradientu proksymalnego .
Metoda pędu lub ciężkiej piłki
Próbując przełamać zygzakowaty wzór opadania gradientu, metoda pędu lub ciężkiej kuli wykorzystuje termin pędu w analogii do ciężkiej kuli ślizgającej się po powierzchni minimalizowanych wartości funkcji lub do ruchu masy w dynamice newtonowskiej przez lepki medium w konserwatywnym polu siłowym. Spadek gradientu z pędem zapamiętuje aktualizację rozwiązania w każdej iteracji i określa następną aktualizację jako liniową kombinację gradientu i poprzedniej aktualizacji. W przypadku nieograniczonej minimalizacji kwadratowej teoretyczna granica szybkości zbieżności metody ciężkiej kuli jest asymptotycznie taka sama jak w przypadku optymalnej metody gradientu sprzężonego .
Ta technika jest używana w stochastycznym zejściu gradientowym#Momentum oraz jako rozszerzenie algorytmów wstecznej propagacji błędów używanych do trenowania sztucznych sieci neuronowych .
Rozszerzenia
Opadanie gradientowe można rozszerzyć w celu obsługi wiązań , dołączając rzutowanie na zestaw wiązań. Ta metoda jest możliwa tylko wtedy, gdy projekcja jest wydajnie obliczana na komputerze. Przy odpowiednich założeniach metoda ta jest zbieżna. Metoda ta jest szczególnym przypadkiem algorytmu przód-tył dla wtrąceń monotonicznych (obejmującego programowanie wypukłe i nierówności wariacyjne ).
Zobacz też
- Wyszukiwanie linii z wycofywaniem
- Metoda gradientu sprzężonego
- Stochastyczne zejście gradientowe
- Rprop
- Reguła delta
- Warunki Wolfe
- Wstępne uwarunkowanie
- Algorytm Broydena-Fletchera-Goldfarba-Shanno
- Wzór Davidona-Fletchera-Powella
- Metoda Nelder-Mead
- Algorytm Gaussa-Newtona
- wspinaczka górska
- Wyżarzanie kwantowe
- Ciągłe wyszukiwanie lokalne
Bibliografia
Dalsza lektura
- Boyda, Stephena ; Vandenberghe, Lieven (2004). „Nieograniczona minimalizacja” (PDF) . Optymalizacja wypukła . Nowy Jork: Cambridge University Press. s. 457–520. Numer ISBN 0-521-83378-7.
- Chong, Edwin KP; Żak, Stanisław H. (2013). „Metody gradientowe” . Wprowadzenie do optymalizacji (wyd. czwarte). Hoboken: Wiley. s. 131–160. Numer ISBN 978-1-118-27901-4.
- Himmelblau, David M. (1972). „Nieograniczone procedury minimalizacji przy użyciu pochodnych”. Stosowane programowanie nieliniowe . Nowy Jork: McGraw-Hill. s. 63–132. Numer ISBN 0-07-028921-2.
Zewnętrzne linki
- Korzystanie z gradientu w C++, Boost, Ublas do regresji liniowej
- Seria filmów Khan Academy omawia wznoszenie gradientowe
- Książka online ucząca opadania gradientu w kontekście głębokich sieci neuronowych
- „Spadek gradientu, jak uczą się sieci neuronowe” . 3Niebieski1Brązowy . 16 października 2017 – przez YouTube .
arxiv.org/2108.1283